当前位置:
X-MOL 学术
›
J. Chem. Inf. Model.
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
Novel Consensus Architecture To Improve Performance of Large-Scale Multitask Deep Learning QSAR Models.
Journal of Chemical Information and Modeling ( IF 5.6 ) Pub Date : 2019-10-25 , DOI: 10.1021/acs.jcim.9b00526 Alexey V Zakharov 1 , Tongan Zhao 1 , Dac-Trung Nguyen 1 , Tyler Peryea 1 , Timothy Sheils 1 , Adam Yasgar 1 , Ruili Huang 1 , Noel Southall 1 , Anton Simeonov 1
Journal of Chemical Information and Modeling ( IF 5.6 ) Pub Date : 2019-10-25 , DOI: 10.1021/acs.jcim.9b00526 Alexey V Zakharov 1 , Tongan Zhao 1 , Dac-Trung Nguyen 1 , Tyler Peryea 1 , Timothy Sheils 1 , Adam Yasgar 1 , Ruili Huang 1 , Noel Southall 1 , Anton Simeonov 1
Affiliation
|
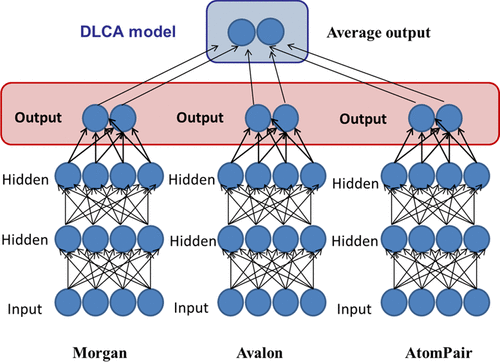
Advances in the development of high-throughput screening and automated chemistry have rapidly accelerated the production of chemical and biological data, much of them freely accessible through literature aggregator services such as ChEMBL and PubChem. Here, we explore how to use this comprehensive mapping of chemical biology space to support the development of large-scale quantitative structure-activity relationship (QSAR) models. We propose a new deep learning consensus architecture (DLCA) that combines consensus and multitask deep learning approaches together to generate large-scale QSAR models. This method improves knowledge transfer across different target/assays while also integrating contributions from models based on different descriptors. The proposed approach was validated and compared with proteochemometrics, multitask deep learning, and Random Forest methods paired with various descriptors types. DLCA models demonstrated improved prediction accuracy for both regression and classification tasks. The best models together with their modeling sets are provided through publicly available web services at https://predictor.ncats.io .
中文翻译:

提高大规模多任务深度学习 QSAR 模型性能的新型共识架构。
高通量筛选和自动化化学发展的进步迅速加速了化学和生物数据的产生,其中大部分数据可通过文献聚合服务(如 ChEMBL 和 PubChem)免费访问。在这里,我们探索如何使用这种化学生物学空间的综合映射来支持大规模定量构效关系 (QSAR) 模型的开发。我们提出了一种新的深度学习共识架构 (DLCA),它将共识和多任务深度学习方法结合在一起以生成大规模 QSAR 模型。该方法改进了跨不同目标/检测的知识转移,同时还整合了基于不同描述符的模型的贡献。所提出的方法经过验证并与蛋白质化学计量学、多任务深度学习、和随机森林方法与各种描述符类型配对。DLCA 模型证明了回归和分类任务的预测准确性提高。最好的模型及其建模集是通过 https://predictor.ncats.io 上的公开网络服务提供的。
更新日期:2019-10-25
中文翻译:
提高大规模多任务深度学习 QSAR 模型性能的新型共识架构。
高通量筛选和自动化化学发展的进步迅速加速了化学和生物数据的产生,其中大部分数据可通过文献聚合服务(如 ChEMBL 和 PubChem)免费访问。在这里,我们探索如何使用这种化学生物学空间的综合映射来支持大规模定量构效关系 (QSAR) 模型的开发。我们提出了一种新的深度学习共识架构 (DLCA),它将共识和多任务深度学习方法结合在一起以生成大规模 QSAR 模型。该方法改进了跨不同目标/检测的知识转移,同时还整合了基于不同描述符的模型的贡献。所提出的方法经过验证并与蛋白质化学计量学、多任务深度学习、和随机森林方法与各种描述符类型配对。DLCA 模型证明了回归和分类任务的预测准确性提高。最好的模型及其建模集是通过 https://predictor.ncats.io 上的公开网络服务提供的。

















































 京公网安备 11010802027423号
京公网安备 11010802027423号