当前位置:
X-MOL 学术
›
Water Res.
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
How small is big enough? Big data-driven machine learning predictions for a full-scale wastewater treatment plant
Water Research ( IF 11.4 ) Pub Date : 2024-12-25 , DOI: 10.1016/j.watres.2024.123041 Yanyan Ma, Yiheng Qiao, Mengxue Chen, Dongni Rui, Xuxiang Zhang, Weijing Liu, Lin Ye
Water Research ( IF 11.4 ) Pub Date : 2024-12-25 , DOI: 10.1016/j.watres.2024.123041 Yanyan Ma, Yiheng Qiao, Mengxue Chen, Dongni Rui, Xuxiang Zhang, Weijing Liu, Lin Ye
|
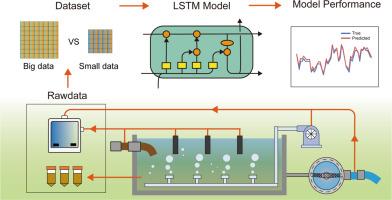
Wastewater treatment plants (WWTPs) generate vast amounts of water quality, operational, and biological data. The potential of these big data, particularly through machine learning (ML), to improve WWTP management is increasingly recognized. However, the costs associated with data collection and processing can rise sharply as datasets grow larger, and research on determining the optimal data volume for effective ML application remains limited. In this study, we comprehensively analyzed water quality, operational, and biological data collected from a full-scale WWTP over 970 days. Our results demonstrate that ML models can predict not only operational and water quality parameters (concentrations of dissolved oxygen and effluent chemical oxygen demand) but also the abundances of functional bacteria. Notably, we discovered that increasing data volume does not always improve model performance, and that data collection intervals do not need to be excessively small, as moderate intervals can still yield reliable predictions. These findings suggest that excessively large datasets may not be necessary for effective ML predictions in WWTPs. Overall, this study underscores the importance of optimizing dataset size to balance computation efficiency and prediction accuracy, providing valuable insights into data management strategies that can enhance the operational efficiency and sustainability of WWTPs.
中文翻译:

多小才算足够大?大数据驱动的机器学习预测,适用于大型污水处理厂
污水处理厂 (WWTP) 会产生大量的水质、运营和生物数据。这些大数据,特别是通过机器学习 (ML) 改进 WWTP 管理的潜力,越来越受到认可。但是,随着数据集的增加,与数据收集和处理相关的成本可能会急剧上升,并且确定有效 ML 应用程序的最佳数据量的研究仍然有限。在这项研究中,我们全面分析了 970 天内从全尺寸 WWTP 收集的水质、运营和生物数据。我们的结果表明,ML 模型不仅可以预测运营和水质参数(溶解氧浓度和出水化学需氧量),还可以预测功能性细菌的丰度。值得注意的是,我们发现增加数据量并不总是能提高模型性能,并且数据收集间隔不需要过小,因为适度的间隔仍然可以产生可靠的预测。这些发现表明,在污水处理厂中进行有效的 ML 预测可能不需要过大的数据集。总体而言,本研究强调了优化数据集大小以平衡计算效率和预测准确性的重要性,为可以提高污水处理厂运营效率和可持续性的数据管理策略提供了有价值的见解。
更新日期:2024-12-30
中文翻译:
多小才算足够大?大数据驱动的机器学习预测,适用于大型污水处理厂
污水处理厂 (WWTP) 会产生大量的水质、运营和生物数据。这些大数据,特别是通过机器学习 (ML) 改进 WWTP 管理的潜力,越来越受到认可。但是,随着数据集的增加,与数据收集和处理相关的成本可能会急剧上升,并且确定有效 ML 应用程序的最佳数据量的研究仍然有限。在这项研究中,我们全面分析了 970 天内从全尺寸 WWTP 收集的水质、运营和生物数据。我们的结果表明,ML 模型不仅可以预测运营和水质参数(溶解氧浓度和出水化学需氧量),还可以预测功能性细菌的丰度。值得注意的是,我们发现增加数据量并不总是能提高模型性能,并且数据收集间隔不需要过小,因为适度的间隔仍然可以产生可靠的预测。这些发现表明,在污水处理厂中进行有效的 ML 预测可能不需要过大的数据集。总体而言,本研究强调了优化数据集大小以平衡计算效率和预测准确性的重要性,为可以提高污水处理厂运营效率和可持续性的数据管理策略提供了有价值的见解。






























 京公网安备 11010802027423号
京公网安备 11010802027423号