Nature Human Behaviour ( IF 21.4 ) Pub Date : 2024-12-20 , DOI: 10.1038/s41562-024-01961-1 Alexandru Marcoci, David P. Wilkinson, Ans Vercammen, Bonnie C. Wintle, Anna Lou Abatayo, Ernest Baskin, Henk Berkman, Erin M. Buchanan, Sara Capitán, Tabaré Capitán, Ginny Chan, Kent Jason G. Cheng, Tom Coupé, Sarah Dryhurst, Jianhua Duan, John E. Edlund, Timothy M. Errington, Anna Fedor, Fiona Fidler, James G. Field, Nicholas Fox, Hannah Fraser, Alexandra L. J. Freeman, Anca Hanea, Felix Holzmeister, Sanghyun Hong, Raquel Huggins, Nick Huntington-Klein, Magnus Johannesson, Angela M. Jones, Hansika Kapoor, John Kerr, Melissa Kline Struhl, Marta Kołczyńska, Yang Liu, Zachary Loomas, Brianna Luis, Esteban Méndez, Olivia Miske, Fallon Mody, Carolin Nast, Brian A. Nosek, E. Simon Parsons, Thomas Pfeiffer, W. Robert Reed, Jon Roozenbeek, Alexa R. Schlyfestone, Claudia R. Schneider, Andrew Soh, Zhongchen Song, Anirudh Tagat, Melba Tutor, Andrew H. Tyner, Karolina Urbanska, Sander van der Linden
|
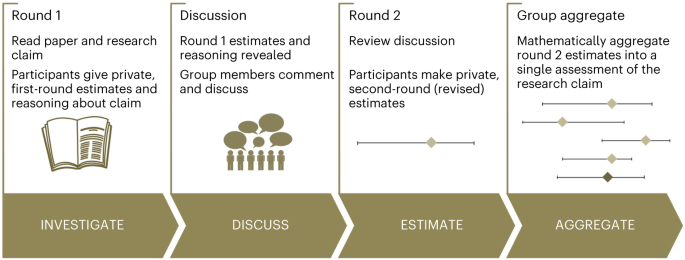
Replications are important for assessing the reliability of published findings. However, they are costly, and it is infeasible to replicate everything. Accurate, fast, lower-cost alternatives such as eliciting predictions could accelerate assessment for rapid policy implementation in a crisis and help guide a more efficient allocation of scarce replication resources. We elicited judgements from participants on 100 claims from preprints about an emerging area of research (COVID-19 pandemic) using an interactive structured elicitation protocol, and we conducted 29 new high-powered replications. After interacting with their peers, participant groups with lower task expertise (‘beginners’) updated their estimates and confidence in their judgements significantly more than groups with greater task expertise (‘experienced’). For experienced individuals, the average accuracy was 0.57 (95% CI: [0.53, 0.61]) after interaction, and they correctly classified 61% of claims; beginners’ average accuracy was 0.58 (95% CI: [0.54, 0.62]), correctly classifying 69% of claims. The difference in accuracy between groups was not statistically significant and their judgements on the full set of claims were correlated (r(98) = 0.48, P < 0.001). These results suggest that both beginners and more-experienced participants using a structured process have some ability to make better-than-chance predictions about the reliability of ‘fast science’ under conditions of high uncertainty. However, given the importance of such assessments for making evidence-based critical decisions in a crisis, more research is required to understand who the right experts in forecasting replicability are and how their judgements ought to be elicited.





























 京公网安备 11010802027423号
京公网安备 11010802027423号