当前位置:
X-MOL 学术
›
Anal. Chem.
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
Introducing “Identification Probability” for Automated and Transferable Assessment of Metabolite Identification Confidence in Metabolomics and Related Studies
Analytical Chemistry ( IF 6.7 ) Pub Date : 2024-12-19 , DOI: 10.1021/acs.analchem.4c04060 Thomas O. Metz, Christine H. Chang, Vasuk Gautam, Afia Anjum, Siyang Tian, Fei Wang, Sean M. Colby, Jamie R. Nunez, Madison R. Blumer, Arthur S. Edison, Oliver Fiehn, Dean P. Jones, Shuzhao Li, Edward T. Morgan, Gary J. Patti, Dylan H. Ross, Madelyn R. Shapiro, Antony J. Williams, David S. Wishart
Analytical Chemistry ( IF 6.7 ) Pub Date : 2024-12-19 , DOI: 10.1021/acs.analchem.4c04060 Thomas O. Metz, Christine H. Chang, Vasuk Gautam, Afia Anjum, Siyang Tian, Fei Wang, Sean M. Colby, Jamie R. Nunez, Madison R. Blumer, Arthur S. Edison, Oliver Fiehn, Dean P. Jones, Shuzhao Li, Edward T. Morgan, Gary J. Patti, Dylan H. Ross, Madelyn R. Shapiro, Antony J. Williams, David S. Wishart
|
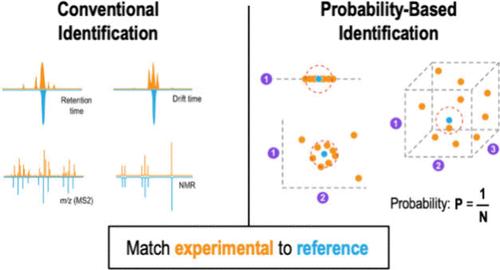
Methods for assessing compound identification confidence in metabolomics and related studies have been debated and actively researched for the past two decades. The earliest effort in 2007 focused primarily on mass spectrometry and nuclear magnetic resonance spectroscopy and resulted in four recommended levels of metabolite identification confidence─the Metabolite Standards Initiative (MSI) Levels. In 2014, the original MSI Levels were expanded to five levels (including two sublevels) to facilitate communication of compound identification confidence in high resolution mass spectrometry studies. Further refinement in identification levels have occurred, for example to accommodate use of ion mobility spectrometry in metabolomics workflows, and alternate approaches to communicate compound identification confidence also have been developed based on identification points schema. However, neither qualitative levels of identification confidence nor quantitative scoring systems address the degree of ambiguity in compound identifications in the context of the chemical space being considered. Neither are they easily automated nor transferable between analytical platforms. In this perspective, we propose that the metabolomics and related communities consider identification probability as an approach for automated and transferable assessment of compound identification and ambiguity in metabolomics and related studies. Identification probability is defined simply as 1/N, where N is the number of compounds in a database that matches an experimentally measured molecule within user-defined measurement precision(s), for example mass measurement or retention time accuracy, etc. We demonstrate the utility of identification probability in an in silico analysis of multiproperty reference libraries constructed from a subset of the Human Metabolome Database and computational property predictions, provide guidance to the community in transparent implementation of the concept, and invite the community to further evaluate this concept in parallel with their current preferred methods for assessing metabolite identification confidence.
中文翻译:

引入“鉴定概率”,用于代谢组学和相关研究中代谢物鉴定置信度的自动化和可转移评估
在过去的二十年里,在代谢组学和相关研究中评估化合物鉴定可信度的方法一直在争论和积极研究。2007 年,最早的工作主要集中在质谱和核磁共振波谱上,并产生了四个推荐的代谢物鉴定置信度水平——代谢物标准品倡议 (MSI) 水平。2014 年,原来的 MSI 水平扩展到五个级别(包括两个子级别),以促进在高分辨率质谱研究中传达化合物鉴定的可信度。鉴定水平得到了进一步改进,例如,为了适应在代谢组学工作流程中使用离子淌度质谱法,并且还开发了基于鉴定点方案的替代方法来传达化合物鉴定的可信度。然而,鉴定置信度的定性水平和定量评分系统都没有解决所考虑的化学空间背景下化合物鉴定的模糊程度。它们既不容易自动化,也不能在分析平台之间转移。从这个角度来看,我们建议代谢组学和相关社区将鉴定概率视为代谢组学和相关研究中化合物鉴定和模糊性的自动化和可转移评估的一种方法。鉴定概率简单地定义为 1/N,其中 N 是数据库中与实验测量分子相匹配的化合物数量,在用户定义的测量精度范围内,例如质量测量或保留时间准确度等。 我们展示了识别概率在由人类代谢组数据库子集和计算特性预测构建的多属性参考库的计算机分析中的效用,为社区透明地实施该概念提供指导,并邀请社区进一步评估这一概念与他们目前首选的评估代谢物鉴定置信度的方法并行。
更新日期:2024-12-19
中文翻译:
引入“鉴定概率”,用于代谢组学和相关研究中代谢物鉴定置信度的自动化和可转移评估
在过去的二十年里,在代谢组学和相关研究中评估化合物鉴定可信度的方法一直在争论和积极研究。2007 年,最早的工作主要集中在质谱和核磁共振波谱上,并产生了四个推荐的代谢物鉴定置信度水平——代谢物标准品倡议 (MSI) 水平。2014 年,原来的 MSI 水平扩展到五个级别(包括两个子级别),以促进在高分辨率质谱研究中传达化合物鉴定的可信度。鉴定水平得到了进一步改进,例如,为了适应在代谢组学工作流程中使用离子淌度质谱法,并且还开发了基于鉴定点方案的替代方法来传达化合物鉴定的可信度。然而,鉴定置信度的定性水平和定量评分系统都没有解决所考虑的化学空间背景下化合物鉴定的模糊程度。它们既不容易自动化,也不能在分析平台之间转移。从这个角度来看,我们建议代谢组学和相关社区将鉴定概率视为代谢组学和相关研究中化合物鉴定和模糊性的自动化和可转移评估的一种方法。鉴定概率简单地定义为 1/N,其中 N 是数据库中与实验测量分子相匹配的化合物数量,在用户定义的测量精度范围内,例如质量测量或保留时间准确度等。 我们展示了识别概率在由人类代谢组数据库子集和计算特性预测构建的多属性参考库的计算机分析中的效用,为社区透明地实施该概念提供指导,并邀请社区进一步评估这一概念与他们目前首选的评估代谢物鉴定置信度的方法并行。
































 京公网安备 11010802027423号
京公网安备 11010802027423号