Nature Machine Intelligence ( IF 18.8 ) Pub Date : 2024-12-18 , DOI: 10.1038/s42256-024-00935-2 D. S. Matthews, M. A. Spence, A. C. Mater, J. Nichols, S. B. Pulsford, M. Sandhu, J. A. Kaczmarski, C. M. Miton, N. Tokuriki, C. J. Jackson
|
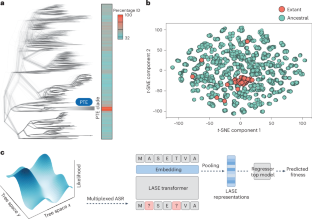
Protein language models (PLMs) convert amino acid sequences into the numerical representations required to train machine learning models. Many PLMs are large (>600 million parameters) and trained on a broad span of protein sequence space. However, these models have limitations in terms of predictive accuracy and computational cost. Here we use multiplexed ancestral sequence reconstruction to generate small but focused functional protein sequence datasets for PLM training. Compared to large PLMs, this local ancestral sequence embedding produces representations with higher predictive accuracy. We show that due to the evolutionary nature of the ancestral sequence reconstruction data, local ancestral sequence embedding produces smoother fitness landscapes, in which protein variants that are closer in fitness value become numerically closer in representation space. This work contributes to the implementation of machine learning-based protein design in real-world settings, where data are sparse and computational resources are limited.
中文翻译:
利用祖先序列重建进行蛋白质表征学习
蛋白质语言模型 (PLM) 将氨基酸序列转换为训练机器学习模型所需的数字表示。许多 PLM 很大(>6 亿个参数),并且在广泛的蛋白质序列空间上进行训练。但是,这些模型在预测准确性和计算成本方面存在局限性。在这里,我们使用多重祖先序列重建来生成用于 PLM 训练的小但聚焦的功能蛋白质序列数据集。与大型 PLM 相比,这种局部祖先序列嵌入产生的表示具有更高的预测准确性。我们表明,由于祖先序列重建数据的进化性质,局部祖先序列嵌入产生了更平滑的适应度景观,其中适应度值更接近的蛋白质变体在表示空间中在数值上更接近。这项工作有助于在数据稀疏且计算资源有限的现实世界环境中实现基于机器学习的蛋白质设计。
































 京公网安备 11010802027423号
京公网安备 11010802027423号