Nature Biomedical Engineering ( IF 26.8 ) Pub Date : 2024-12-06 , DOI: 10.1038/s41551-024-01284-6 Yiqun Chen, James Zou
|
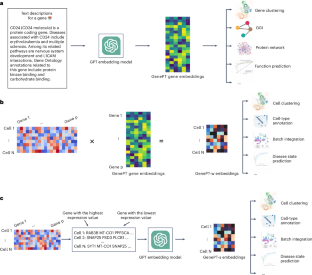
Large-scale gene-expression data are being leveraged to pretrain models that implicitly learn gene and cellular functions. However, such models require extensive data curation and training. Here we explore a much simpler alternative: leveraging ChatGPT embeddings of genes based on the literature. We used GPT-3.5 to generate gene embeddings from text descriptions of individual genes and to then generate single-cell embeddings by averaging the gene embeddings weighted by each gene’s expression level. We also created a sentence embedding for each cell by using only the gene names ordered by their expression level. On many downstream tasks used to evaluate pretrained single-cell embedding models—particularly, tasks of gene-property and cell-type classifications—our model, which we named GenePT, achieved comparable or better performance than models pretrained from gene-expression profiles of millions of cells. GenePT shows that large-language-model embeddings of the literature provide a simple and effective path to encoding single-cell biological knowledge.
中文翻译:
从 ChatGPT 构建的简单有效的单细胞生物学嵌入模型
大规模基因表达数据被用于预训练隐式学习基因和细胞功能的模型。但是,此类模型需要大量的数据管理和训练。在这里,我们探索了一个更简单的替代方案:利用基于文献的 ChatGPT 基因嵌入。我们使用 GPT-3.5 从单个基因的文本描述中生成基因嵌入,然后通过平均按每个基因的表达水平加权的基因嵌入来生成单细胞嵌入。我们还通过仅使用按表达水平排序的基因名称,为每个细胞创建了一个句子嵌入。在用于评估预训练的单细胞包埋模型的许多下游任务中,特别是基因特性和细胞类型分类的任务,我们的模型(我们命名为 GenePT)实现了与从数百万个细胞的基因表达谱预训练的模型相当或更好的性能。GenePT 表明,文献的大型语言模型嵌入为编码单细胞生物学知识提供了一种简单有效的途径。
































 京公网安备 11010802027423号
京公网安备 11010802027423号