Nature Photonics ( IF 32.3 ) Pub Date : 2024-12-02 , DOI: 10.1038/s41566-024-01567-z Saumil Bandyopadhyay, Alexander Sludds, Stefan Krastanov, Ryan Hamerly, Nicholas Harris, Darius Bunandar, Matthew Streshinsky, Michael Hochberg, Dirk Englund
|
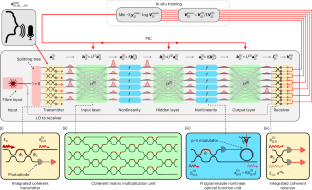
As deep neural networks revolutionize machine learning, energy consumption and throughput are emerging as fundamental limitations of complementary metal–oxide–semiconductor (CMOS) electronics. This has motivated a search for new hardware architectures optimized for artificial intelligence, such as electronic systolic arrays, memristor crossbar arrays and optical accelerators. Optical systems can perform linear matrix operations at an exceptionally high rate and efficiency, motivating recent demonstrations of low-latency matrix accelerators and optoelectronic image classifiers. However, demonstrating coherent, ultralow-latency optical processing of deep neural networks has remained an outstanding challenge. Here we realize such a system in a scalable photonic integrated circuit that monolithically integrates multiple coherent optical processor units for matrix algebra and nonlinear activation functions into a single chip. We experimentally demonstrate this fully integrated coherent optical neural network architecture for a deep neural network with six neurons and three layers that optically computes both linear and nonlinear functions with a latency of 410 ps, unlocking new applications that require ultrafast, direct processing of optical signals. We implement backpropagation-free in situ training on this system, achieving 92.5% accuracy on a six-class vowel classification task, which is comparable to the accuracy obtained on a digital computer. This work lends experimental evidence to theoretical proposals for in situ training, enabling orders of magnitude improvements in the throughput of training data. Moreover, the fully integrated coherent optical neural network opens the path to inference at nanosecond latency and femtojoule per operation energy efficiency.
中文翻译:
具有仅前向训练的单芯片光子深度神经网络
随着深度神经网络彻底改变机器学习,能耗和吞吐量正在成为互补金属氧化物半导体 (CMOS) 电子学的基本限制。这促使人们寻找针对人工智能优化的新硬件架构,例如电子脉动阵列、忆阻器交叉开关阵列和光加速器。光学系统可以以极高的速率和效率执行线性矩阵运算,这激发了最近低延迟矩阵加速器和光电图像分类器的演示。然而,展示深度神经网络的连贯、超低延迟光学处理仍然是一个突出的挑战。在这里,我们在可扩展的光子集成电路中实现了这样一个系统,该系统将用于矩阵代数和非线性激活函数的多个相干光处理器单元单片集成到单个芯片中。我们通过实验演示了这种完全集成的相干光学神经网络架构,该架构适用于具有 6 个神经元和 3 层的深度神经网络,该网络以 410 ps 的延迟对线性和非线性函数进行光学计算,从而解锁了需要超快速、直接处理光信号的新应用。我们在该系统上实现了无反向传播的原位训练,在六类元音分类任务中实现了 92.5% 的准确率,这与在数字计算机上获得的准确性相当。这项工作为原位训练的理论建议提供了实验证据,使训练数据的吞吐量提高了几个数量级。此外,完全集成的相干光学神经网络开辟了以纳秒级延迟和飞焦耳每次操作能效进行推理的途径。





























 京公网安备 11010802027423号
京公网安备 11010802027423号