当前位置:
X-MOL 学术
›
J. Hazard. Mater.
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
The development of classification-based machine-learning models for the toxicity assessment of chemicals associated with plastic packaging
Journal of Hazardous Materials ( IF 12.2 ) Pub Date : 2024-11-30 , DOI: 10.1016/j.jhazmat.2024.136702 Md Mobarak Hossain, Kunal Roy
Journal of Hazardous Materials ( IF 12.2 ) Pub Date : 2024-11-30 , DOI: 10.1016/j.jhazmat.2024.136702 Md Mobarak Hossain, Kunal Roy
|
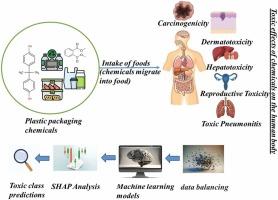
Assessing chemical toxicity in materials like plastic packaging is critical to safeguarding public health. This study presents the development of classification-based machine learning models to predict the toxicity of chemicals associated with plastic packaging. Using an extensive dataset of chemical structures, we trained multiple machine learning models—Random Forest, Support Vector Machine, Linear Discriminant Analysis, and Logistic Regression—targeting endpoints such as Neurotoxicity, Hepatotoxicity, Dermatotoxicity, Carcinogenicity, Reproductive Toxicity, Skin Sensitization, and Toxic Pneumonitis. The dataset was pre-processed by selecting 2D molecular descriptors as feature inputs, with resampling methods (ADASYN, Borderline SMOTE, Random Over-sampler, SVMSMOTE Cluster Centroid, Near Miss, Random Under Sampler) applied to balance classes for accurate classification. A five-fold cross-validation technique was used to optimize model performance, with model parameters fine-tuned using grid search. The model performance was evaluated using accuracy (Acc), sensitivity (Se), specificity (Sp), and area under the receiver operating characteristic curve (AUC-ROC) metrics. In most of the cases, the model accuracy was 0.8 or above for both training and test sets. Additionally, SHAP (SHapley Additive exPlanations) values were utilized for feature importance analysis, highlighting significant descriptors contributing to toxicity predictions. The models were ranked using the Sum of Ranking Differences (SRD) method to systematically select the most effective model. The optimal models demonstrated high predictive accuracy and interpretability, providing a scalable and efficient solution for toxicity assessment compared to traditional methods. This approach offers a valuable tool for rapidly screening potentially hazardous chemicals in plastic packaging.
中文翻译:

开发基于分类的机器学习模型,用于评估与塑料包装相关的化学品的毒性
评估塑料包装等材料的化学毒性对于保护公众健康至关重要。本研究介绍了基于分类的机器学习模型的开发,以预测与塑料包装相关的化学品的毒性。使用广泛的化学结构数据集,我们训练了多个机器学习模型——随机森林、支持向量机、线性判别分析和逻辑回归——针对神经毒性、肝毒性、皮肤毒性、致癌性、生殖毒性、皮肤致敏和中毒性肺炎等终点。通过选择 2D 分子描述符作为特征输入对数据集进行预处理,并应用重采样方法 (ADASYN、Borderline SMOTE、Random Over-sampler、SVMSMOTE Cluster Centroid、Near Miss、Random Under Sampler) 来平衡类以实现准确分类。使用五重交叉验证技术来优化模型性能,并使用网格搜索对模型参数进行微调。使用准确性 (Acc) 、敏感性 (Se) 、特异性 (Sp) 和受试者工作特征曲线下面积 (AUC-ROC) 指标评估模型性能。在大多数情况下,训练集和测试集的模型准确率均为 0.8 或更高。此外,SHAP (SHapley Additive explanations) 值用于特征重要性分析,突出显示有助于毒性预测的重要描述符。使用 Sum of Ranking Differences (SRD) 方法对模型进行排名,以系统地选择最有效的模型。与传统方法相比,最佳模型表现出高预测准确性和可解释性,为毒性评估提供了可扩展且高效的解决方案。 这种方法为快速筛查塑料包装中的潜在危险化学品提供了有价值的工具。
更新日期:2024-11-30
中文翻译:
开发基于分类的机器学习模型,用于评估与塑料包装相关的化学品的毒性
评估塑料包装等材料的化学毒性对于保护公众健康至关重要。本研究介绍了基于分类的机器学习模型的开发,以预测与塑料包装相关的化学品的毒性。使用广泛的化学结构数据集,我们训练了多个机器学习模型——随机森林、支持向量机、线性判别分析和逻辑回归——针对神经毒性、肝毒性、皮肤毒性、致癌性、生殖毒性、皮肤致敏和中毒性肺炎等终点。通过选择 2D 分子描述符作为特征输入对数据集进行预处理,并应用重采样方法 (ADASYN、Borderline SMOTE、Random Over-sampler、SVMSMOTE Cluster Centroid、Near Miss、Random Under Sampler) 来平衡类以实现准确分类。使用五重交叉验证技术来优化模型性能,并使用网格搜索对模型参数进行微调。使用准确性 (Acc) 、敏感性 (Se) 、特异性 (Sp) 和受试者工作特征曲线下面积 (AUC-ROC) 指标评估模型性能。在大多数情况下,训练集和测试集的模型准确率均为 0.8 或更高。此外,SHAP (SHapley Additive explanations) 值用于特征重要性分析,突出显示有助于毒性预测的重要描述符。使用 Sum of Ranking Differences (SRD) 方法对模型进行排名,以系统地选择最有效的模型。与传统方法相比,最佳模型表现出高预测准确性和可解释性,为毒性评估提供了可扩展且高效的解决方案。 这种方法为快速筛查塑料包装中的潜在危险化学品提供了有价值的工具。
































 京公网安备 11010802027423号
京公网安备 11010802027423号