Nature Communications ( IF 14.7 ) Pub Date : 2024-11-20 , DOI: 10.1038/s41467-024-53340-z Viktoria Schuster, Emma Dann, Anders Krogh, Sarah A. Teichmann
|
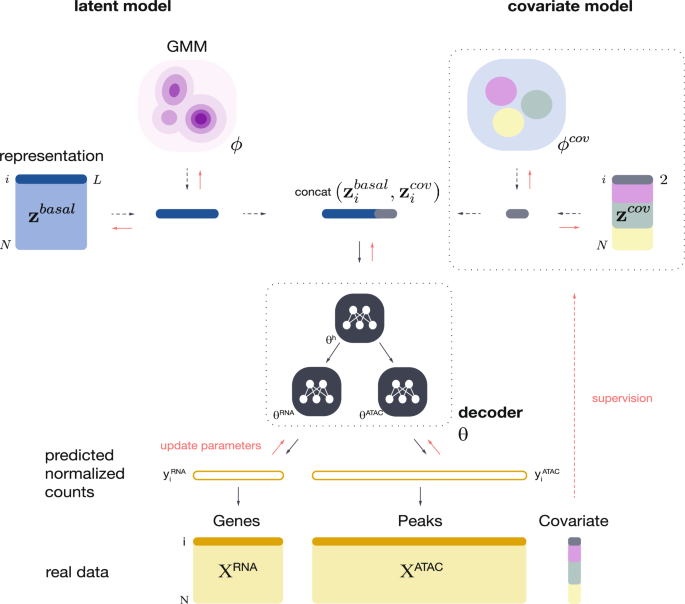
Recent technological advancements in single-cell genomics have enabled joint profiling of gene expression and alternative modalities at unprecedented scale. Consequently, the complexity of multi-omics data sets is increasing massively. Existing models for multi-modal data are typically limited in functionality or scalability, making data integration and downstream analysis cumbersome. We present multiDGD, a scalable deep generative model providing a probabilistic framework to learn shared representations of transcriptome and chromatin accessibility. It shows outstanding performance on data reconstruction without feature selection. We demonstrate on several data sets from human and mouse that multiDGD learns well-clustered joint representations. We further find that probabilistic modeling of sample covariates enables post-hoc data integration without the need for fine-tuning. Additionally, we show that multiDGD can detect statistical associations between genes and regulatory regions conditioned on the learned representations. multiDGD is available as an scverse-compatible package on GitHub.
中文翻译:
multiDGD:用于多组学数据的多功能深度生成模型
单细胞基因组学的最新技术进步使基因表达和替代模式的联合分析成为可能,规模空前。因此,多组学数据集的复杂性正在大幅增加。现有的多模态数据模型通常在功能或可扩展性方面受到限制,这使得数据集成和下游分析变得繁琐。我们提出了 multiDGD,这是一种可扩展的深度生成模型,提供了一个概率框架来学习转录组和染色质可及性的共享表示。它在无特征选择的数据重建方面表现出出色的性能。我们在人类和小鼠的几个数据集上演示了 multiDGD 学习了聚类良好的关节表示。我们进一步发现,样本协变量的概率建模可以在不需要微调的情况下进行事后数据集成。此外,我们表明 multiDGD 可以检测基因和调节区域之间的统计关联,具体取决于学习的表征。multiDGD 在 GitHub 上作为 scverse 兼容包提供。



















































 京公网安备 11010802027423号
京公网安备 11010802027423号