当前位置:
X-MOL 学术
›
ACS Macro Lett.
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
Modeling of Chain Sequence Length and Distribution in Random Copolyesters
ACS Macro Letters ( IF 5.1 ) Pub Date : 2024-11-15 , DOI: 10.1021/acsmacrolett.4c00598 Yisong Wang, Bingxue Jiang, Zhengqi Peng, Khak Ho Lim, Qingyue Wang, Shengbin Shi, Jieyuan Zheng, Deliang Wang, Xuan Yang, Pingwei Liu, Wen-Jun Wang
ACS Macro Letters ( IF 5.1 ) Pub Date : 2024-11-15 , DOI: 10.1021/acsmacrolett.4c00598 Yisong Wang, Bingxue Jiang, Zhengqi Peng, Khak Ho Lim, Qingyue Wang, Shengbin Shi, Jieyuan Zheng, Deliang Wang, Xuan Yang, Pingwei Liu, Wen-Jun Wang
|
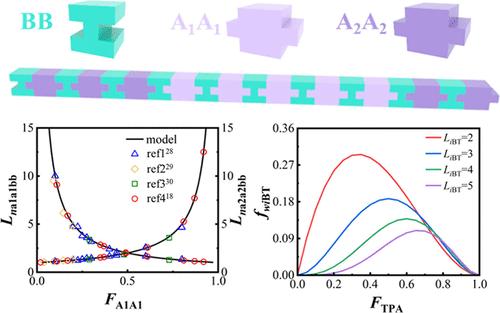
The performances and properties of random copolyesters, including biodegradability, mechanical and thermal properties, transparency, etc., are highly influenced by their chain structures. However, obtaining detailed chain sequence information remains a significant challenge. This study introduces a mathematical model based on a probabilistic approach to determine the sequence length and distribution in random copolyesters. Two types of copolyesters, A1A1BB-A2A2BB, representing poly(butylene adipate-co-terephthalate) (PBAT), and A1A1B1B1-A2B2, using poly(butylene succinate-co-glycolic acid) (PBT–PGA) as an example, are the focus. The predicted sequence lengths of various copolyesters derived from the model are in good agreement with the values reported in the literature. The chain sequence distribution obtained from the model provides better insights into the unique properties of the copolyesters. It is observed that the incorporation of hydroxyl acid units into copolyester chains effectively reduces the sequence length without altering the copolymer composition, offering a strategic approach for enhancing degradation performance while maintaining mechanical properties of random copolyesters. The influence of the number-average sequence length becomes particularly significant when the copolymer composition ranges between 0.7 and 0.9, with a higher copolymer composition required for copolyesters containing hydroxyl acid monomer units. This model represents a powerful tool for researchers, enabling a deeper understanding of the relationship between copolymer composition and its structural characteristics in random copolyesters and facilitating the development of high-performance random copolyesters.
中文翻译:

随机共聚酯中链序长度和分布的建模
无规共聚酯的性能和性能,包括生物降解性、机械和热性能、透明度等,都受其链结构的高度影响。然而,获得详细的链序列信息仍然是一个重大挑战。本研究引入了一个基于概率方法的数学模型,以确定随机共聚酯中的序列长度和分布。两种类型的共聚酯,A1A1BB-A2A2BB,代表聚己二酸丁二醇酯-对苯二酸酯 (PBAT) 和 A1A1B1B1-A 2B2,以聚(丁二酸丁二醇酯-共乙醇酸)(PBT-PGA)为例,是重点。从模型得出的各种共聚酯的预测序列长度与文献中报道的值非常吻合。从模型获得的链序列分布有助于更好地了解共聚酯的独特特性。据观察,羟基酸单元掺入共聚酯链可有效缩短序列长度,而不会改变共聚物组成,为提高降解性能同时保持无规共聚酯的机械性能提供了一种战略方法。当共聚物组成范围在 0.7 和 0.9 之间时,数均序列长度的影响变得特别显著,而含有羟基酸单体单元的共聚物需要更高的共聚物组成。 该模型为研究人员提供了一个强大的工具,可以更深入地了解共聚物组成与其在无规共聚酯中的结构特性之间的关系,并促进高性能无规共聚酯的开发。
更新日期:2024-11-15
中文翻译:
随机共聚酯中链序长度和分布的建模
无规共聚酯的性能和性能,包括生物降解性、机械和热性能、透明度等,都受其链结构的高度影响。然而,获得详细的链序列信息仍然是一个重大挑战。本研究引入了一个基于概率方法的数学模型,以确定随机共聚酯中的序列长度和分布。两种类型的共聚酯,A1A1BB-A2A2BB,代表聚己二酸丁二醇酯-对苯二酸酯 (PBAT) 和 A1A1B1B1-A 2B2,以聚(丁二酸丁二醇酯-共乙醇酸)(PBT-PGA)为例,是重点。从模型得出的各种共聚酯的预测序列长度与文献中报道的值非常吻合。从模型获得的链序列分布有助于更好地了解共聚酯的独特特性。据观察,羟基酸单元掺入共聚酯链可有效缩短序列长度,而不会改变共聚物组成,为提高降解性能同时保持无规共聚酯的机械性能提供了一种战略方法。当共聚物组成范围在 0.7 和 0.9 之间时,数均序列长度的影响变得特别显著,而含有羟基酸单体单元的共聚物需要更高的共聚物组成。 该模型为研究人员提供了一个强大的工具,可以更深入地了解共聚物组成与其在无规共聚酯中的结构特性之间的关系,并促进高性能无规共聚酯的开发。






























 京公网安备 11010802027423号
京公网安备 11010802027423号