当前位置:
X-MOL 学术
›
Agric. For. Meteorol.
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
The influence of calibration data diversity on the performance of temperature-based spring phenology models for forest tree species in Central Europe
Agricultural and Forest Meteorology ( IF 5.6 ) Pub Date : 2024-11-14 , DOI: 10.1016/j.agrformet.2024.110302 A. Picornell, L. Caspersen, E. Luedeling
Agricultural and Forest Meteorology ( IF 5.6 ) Pub Date : 2024-11-14 , DOI: 10.1016/j.agrformet.2024.110302 A. Picornell, L. Caspersen, E. Luedeling
|
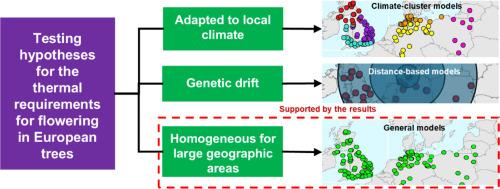
Global temperatures are increasing due to human-driven climate change, with notable implications for the flowering phenology of many forest tree species. Modelling the thermal requirements of these species is critical for projecting the impacts of climate change on forests and for developing appropriate adaptation strategies. Fitting models to phenological observations requires long time series of data, but such data are scarce. Researchers would benefit from combining databases from different locations to fit a single model. The aims of this study are to model the thermal requirements for flowering of the most relevant angiosperm tree species in central Europe and to determine if the accuracy of the models can be improved by limiting the geographic spread of the calibration data. To this end, we fitted the PhenoFlex phenology modelling framework using various subsets of records from the Pan-European Phenology database, which were paired with local temperature data. We used all available data for five species (Acer platanoides, Alnus glutinosa, Betula pendula, Corylus avellana and Fraxinus excelsior ) to fit general thermal requirement models. We also fitted models using subsets of the dataset, limiting the calibration sets to data from climatically homogeneous regions and different geographical extents. The general models had average mean absolute errors of 8.51–15.15 days, indicating that they are effective in forecasting flowering onset for central Europe. Predictions did not improve when fitting models with data from temperature-homogeneous areas or from within small geographical extents. These findings suggest that fitting several models to cover parts of an extensive region does not necessarily perform better than fitting a single model for the whole region. This implies that including data from different locations within central Europe when calibrating models would increase the size of calibration datasets without causing a significant increase in model errors. This may help alleviate problems of data scarcity.
中文翻译:

校准数据多样性对中欧林木物种基于温度的春季物候模型性能的影响
由于人为驱动的气候变化,全球气温正在上升,这对许多森林树种的开花物候产生了显著影响。对这些物种的热需求进行建模对于预测气候变化对森林的影响和制定适当的适应策略至关重要。将模型拟合到物候观测需要长时间序列的数据,但此类数据非常稀缺。研究人员将受益于将来自不同位置的数据库组合在一起以适应单个模型。本研究的目的是对中欧最相关的被子植物树种开花的热需求进行建模,并确定是否可以通过限制校准数据的地理传播来提高模型的准确性。为此,我们使用泛欧物候数据库中的各种记录子集拟合了 PhenoFlex 物候建模框架,这些记录子集与当地温度数据配对。我们使用了五个物种 (Acer platanoides, Alnus glutinosa, Betula pendula, Corylus avellana 和 Fraxinus excelsior) 的所有可用数据来拟合一般的热需求模型。我们还使用数据集的子集拟合模型,将校准集限制为来自气候同质区域和不同地理范围的数据。一般模型的平均绝对误差为 8.51-15.15 天,表明它们在预测中欧开花时间是有效的。当使用来自温度均匀区域或较小地理范围的数据拟合模型时,预测没有改善。这些发现表明,拟合多个模型以覆盖广阔区域的各个部分并不一定比拟合整个区域的单个模型性能更好。 这意味着在校准模型时包含来自中欧不同位置的数据将增加校准数据集的大小,而不会导致模型误差显著增加。这可能有助于缓解数据稀缺的问题。
更新日期:2024-11-14
中文翻译:
校准数据多样性对中欧林木物种基于温度的春季物候模型性能的影响
由于人为驱动的气候变化,全球气温正在上升,这对许多森林树种的开花物候产生了显著影响。对这些物种的热需求进行建模对于预测气候变化对森林的影响和制定适当的适应策略至关重要。将模型拟合到物候观测需要长时间序列的数据,但此类数据非常稀缺。研究人员将受益于将来自不同位置的数据库组合在一起以适应单个模型。本研究的目的是对中欧最相关的被子植物树种开花的热需求进行建模,并确定是否可以通过限制校准数据的地理传播来提高模型的准确性。为此,我们使用泛欧物候数据库中的各种记录子集拟合了 PhenoFlex 物候建模框架,这些记录子集与当地温度数据配对。我们使用了五个物种 (Acer platanoides, Alnus glutinosa, Betula pendula, Corylus avellana 和 Fraxinus excelsior) 的所有可用数据来拟合一般的热需求模型。我们还使用数据集的子集拟合模型,将校准集限制为来自气候同质区域和不同地理范围的数据。一般模型的平均绝对误差为 8.51-15.15 天,表明它们在预测中欧开花时间是有效的。当使用来自温度均匀区域或较小地理范围的数据拟合模型时,预测没有改善。这些发现表明,拟合多个模型以覆盖广阔区域的各个部分并不一定比拟合整个区域的单个模型性能更好。 这意味着在校准模型时包含来自中欧不同位置的数据将增加校准数据集的大小,而不会导致模型误差显著增加。这可能有助于缓解数据稀缺的问题。

















































 京公网安备 11010802027423号
京公网安备 11010802027423号