npj Quantum Information ( IF 6.6 ) Pub Date : 2024-11-13 , DOI: 10.1038/s41534-024-00902-0 Manuel S. Rudolph, Sacha Lerch, Supanut Thanasilp, Oriel Kiss, Oxana Shaya, Sofia Vallecorsa, Michele Grossi, Zoë Holmes
|
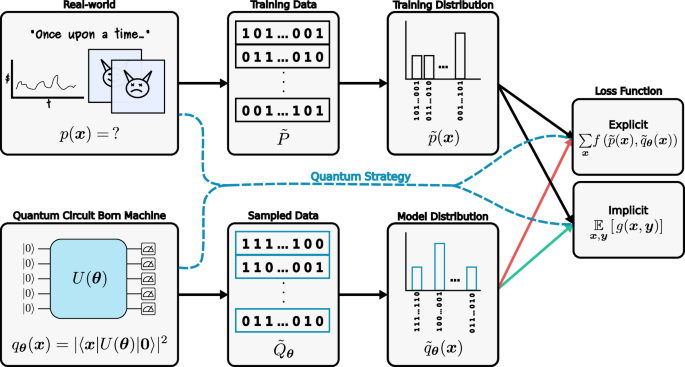
Quantum generative models provide inherently efficient sampling strategies and thus show promise for achieving an advantage using quantum hardware. In this work, we investigate the barriers to the trainability of quantum generative models posed by barren plateaus and exponential loss concentration. We explore the interplay between explicit and implicit models and losses, and show that using quantum generative models with explicit losses such as the KL divergence leads to a new flavor of barren plateaus. In contrast, the implicit Maximum Mean Discrepancy loss can be viewed as the expectation value of an observable that is either low-bodied and provably trainable, or global and untrainable depending on the choice of kernel. In parallel, we find that solely low-bodied implicit losses cannot in general distinguish high-order correlations in the target data, while some quantum loss estimation strategies can. We validate our findings by comparing different loss functions for modeling data from High-Energy-Physics.
中文翻译:
量子生成建模中的可训练性障碍和机会
量子生成模型提供了本质上高效的采样策略,因此有望使用量子硬件实现优势。在这项工作中,我们研究了贫瘠高原和指数损失集中对量子生成模型可训练性的障碍。我们探讨了显式和隐式模型与损失之间的相互作用,并表明使用具有显式损失(例如 KL 散度)的量子生成模型会导致一种新的贫瘠高原。相比之下,隐式 Maximum Mean Discrepancy 损失可以被视为 observable 的期望值,该可观察对象要么是低体且可证明的可训练,要么是全局且不可训练的,具体取决于内核的选择。同时,我们发现,仅低体隐含损失通常无法区分目标数据中的高阶相关性,而一些量子损失估计策略可以。我们通过比较不同的损失函数来验证我们的发现,以对来自 High-Energy-Physics 的数据进行建模。

















































 京公网安备 11010802027423号
京公网安备 11010802027423号