当前位置:
X-MOL 学术
›
J. Chem. Theory Comput.
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
Protein Structure Prediction with High Degrees of Freedom in a Gate-Based Quantum Computer
Journal of Chemical Theory and Computation ( IF 5.7 ) Pub Date : 2024-11-06 , DOI: 10.1021/acs.jctc.4c00848 Jaya Vasavi Pamidimukkala, Soham Bopardikar, Avinash Dakshinamoorthy, Ashwini Kannan, Kalyan Dasgupta, Sanjib Senapati
Journal of Chemical Theory and Computation ( IF 5.7 ) Pub Date : 2024-11-06 , DOI: 10.1021/acs.jctc.4c00848 Jaya Vasavi Pamidimukkala, Soham Bopardikar, Avinash Dakshinamoorthy, Ashwini Kannan, Kalyan Dasgupta, Sanjib Senapati
|
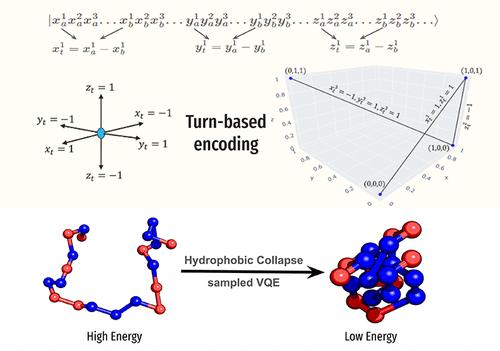
Protein folding, which traces the protein three-dimensional (3D) structure from its amino acid sequence, is a half-a-century-old problem in biology. The function of the protein correlates with its structure, emphasizing the need to study protein folding to understand the cellular and molecular processes better. While recent AI-based methods have shown significant success in protein structure prediction, their accuracy diminishes with proteins of low sequence similarity. Classical simulations face challenges in generating extensive conformational samplings. In this work, we develop a novel turn-based encoding algorithm with more significant degrees of freedom that successfully runs on a gate-based quantum computer and predicts the structure of proteins of varied lengths utilizing up to 114 qubits (IBM hardware). To make the problem tractable in quantum computers, the protein sequences were described with the simplistic HP model (H = hydrophobic residues, P = polar residues). The proposed formulation successfully captures the so-called nucleation step in protein folding, the hydrophobic collapse, that brings the hydrophobic residues to the core of the protein.
中文翻译:

基于门的量子计算机中的高自由度蛋白质结构预测
蛋白质折叠,即从蛋白质的氨基酸序列中追踪蛋白质的三维 (3D) 结构,是生物学中一个已有半个世纪历史的问题。蛋白质的功能与其结构相关,强调需要研究蛋白质折叠以更好地了解细胞和分子过程。虽然最近基于 AI 的方法在蛋白质结构预测方面取得了重大成功,但随着序列相似性低的蛋白质,它们的准确性会降低。经典模拟在生成广泛的构象采样方面面临挑战。在这项工作中,我们开发了一种新颖的基于回合的编码算法,具有更重要的自由度,该算法在基于门的量子计算机上成功运行,并利用多达 114 个量子比特(IBM 硬件)预测不同长度的蛋白质的结构。为了使这个问题在量子计算机中易于处理,用简单的 HP 模型(H = 疏水残基,P = 极性残基)描述了蛋白质序列。拟议的配方成功地捕获了蛋白质折叠中所谓的成核步骤,即疏水塌陷,它将疏水残基带到蛋白质的核心。
更新日期:2024-11-07
中文翻译:
基于门的量子计算机中的高自由度蛋白质结构预测
蛋白质折叠,即从蛋白质的氨基酸序列中追踪蛋白质的三维 (3D) 结构,是生物学中一个已有半个世纪历史的问题。蛋白质的功能与其结构相关,强调需要研究蛋白质折叠以更好地了解细胞和分子过程。虽然最近基于 AI 的方法在蛋白质结构预测方面取得了重大成功,但随着序列相似性低的蛋白质,它们的准确性会降低。经典模拟在生成广泛的构象采样方面面临挑战。在这项工作中,我们开发了一种新颖的基于回合的编码算法,具有更重要的自由度,该算法在基于门的量子计算机上成功运行,并利用多达 114 个量子比特(IBM 硬件)预测不同长度的蛋白质的结构。为了使这个问题在量子计算机中易于处理,用简单的 HP 模型(H = 疏水残基,P = 极性残基)描述了蛋白质序列。拟议的配方成功地捕获了蛋白质折叠中所谓的成核步骤,即疏水塌陷,它将疏水残基带到蛋白质的核心。
































 京公网安备 11010802027423号
京公网安备 11010802027423号