当前位置:
X-MOL 学术
›
Laser Photonics Rev.
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
Diffraction‐Driven Parallel Convolution Processing with Integrated Photonics
Laser & Photonics Reviews ( IF 9.8 ) Pub Date : 2024-10-30 , DOI: 10.1002/lpor.202400972 Yuyao Huang, Wencan Liu, Run Sun, Tingzhao Fu, Yaode Wang, Zheng Huang, Sigang Yang, Hongwei Chen
Laser & Photonics Reviews ( IF 9.8 ) Pub Date : 2024-10-30 , DOI: 10.1002/lpor.202400972 Yuyao Huang, Wencan Liu, Run Sun, Tingzhao Fu, Yaode Wang, Zheng Huang, Sigang Yang, Hongwei Chen
|
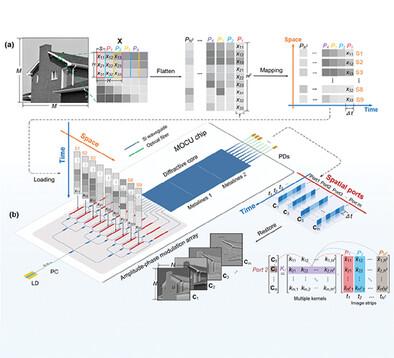
Traditional electronic processors often struggle with bandwidth limitations and high power consumption when executing extensive linear operations for deep learning tasks. Optical computing has emerged as a promising alternative, offering parallel and energy‐efficient computation capabilities. Yet, the development of high‐density optical computing architectures on integrated photonic platforms remains limited, hindered by constraints in neuron scalability and control engineering complexities. Addressing these challenges, this work presents a diffraction‐driven multi‐kernel optical convolution unit (MOCU) that enables on‐chip parallel convolution processing. By utilizing cascaded silica 1D metalines as pre‐trained large‐scale weights and employing spatial multiplexing at the output, MOCU allows simultaneous passive computation of diverse convolutions within a single unit. This architecture facilitates the construction of optical convolutional neural networks (OCNNs), enabling efficient machine vision processing with a streamlined design. To mitigate errors in MOCU‐embedded OCNNs, a lightweight electronic neural network operates concurrently to calibrate systematic deviations via a low‐rank adaptation (LoRA) algorithm, with minimal overhead. The fabricated MOCU chip demonstrates the highest independent 8‐kernel convolutions in parallel, each with a kernel size and occupying just 0.06 . This architecture effectively merges photonic and electronic technologies, offering a scalable design pathway for energy‐efficient, high‐density deep learning hardware.
中文翻译:

集成光子学的衍射驱动并行卷积处理
传统的电子处理器在为深度学习任务执行大量的线性操作时,通常会遇到带宽限制和高功耗的问题。光学计算已成为一种很有前途的替代方案,可提供并行且节能的计算能力。然而,在集成光子平台上开发高密度光计算架构仍然受到限制,受到神经元可扩展性和控制工程复杂性限制的阻碍。为了应对这些挑战,这项工作提出了一种衍射驱动的多核光学卷积单元 (MOCU),可实现片上并行卷积处理。MOCU 利用级联二氧化硅 1D 元线作为预先训练的大规模权重,并在输出端采用空间多路复用,从而允许在单个单元内同时被动计算各种卷积。这种架构有助于构建光学卷积神经网络 (OCNN),从而通过简化的设计实现高效的机器视觉处理。为了减少 MOCU 嵌入式 OCNN 中的误差,轻量级电子神经网络同时运行,通过低秩自适应 (LoRA) 算法校准系统偏差,开销最小。制造的 MOCU 芯片展示了最高的独立 8 核并行卷积,每个卷积的核大小仅为 0.06。这种架构有效地融合了光子和电子技术,为高能效、高密度的深度学习硬件提供了可扩展的设计路径。
更新日期:2024-10-30
中文翻译:
集成光子学的衍射驱动并行卷积处理
传统的电子处理器在为深度学习任务执行大量的线性操作时,通常会遇到带宽限制和高功耗的问题。光学计算已成为一种很有前途的替代方案,可提供并行且节能的计算能力。然而,在集成光子平台上开发高密度光计算架构仍然受到限制,受到神经元可扩展性和控制工程复杂性限制的阻碍。为了应对这些挑战,这项工作提出了一种衍射驱动的多核光学卷积单元 (MOCU),可实现片上并行卷积处理。MOCU 利用级联二氧化硅 1D 元线作为预先训练的大规模权重,并在输出端采用空间多路复用,从而允许在单个单元内同时被动计算各种卷积。这种架构有助于构建光学卷积神经网络 (OCNN),从而通过简化的设计实现高效的机器视觉处理。为了减少 MOCU 嵌入式 OCNN 中的误差,轻量级电子神经网络同时运行,通过低秩自适应 (LoRA) 算法校准系统偏差,开销最小。制造的 MOCU 芯片展示了最高的独立 8 核并行卷积,每个卷积的核大小仅为 0.06。这种架构有效地融合了光子和电子技术,为高能效、高密度的深度学习硬件提供了可扩展的设计路径。

















































 京公网安备 11010802027423号
京公网安备 11010802027423号