International Journal of Computer Vision ( IF 11.6 ) Pub Date : 2024-10-26 , DOI: 10.1007/s11263-024-02277-3 Guifang Zhang, Shijun Tan, Zhe Ji, Yuming Fang
|
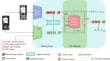
Multimodal based person re-identification (ReID) has garnered increasing attention in recent years. However, the integration of visual and textual information encounters significant challenges. Biases in feature integration are frequently observed in existing methods, resulting in suboptimal performance and restricted generalization across a spectrum of ReID tasks. At the same time, since there is a domain gap between the datasets used by the pretraining model and the ReID datasets, it has a certain impact on the performance. In response to these challenges, we proposed a dynamic attention vision-language transformer network for the ReID task. In this network, a novel image-text dynamic attention module (ITDA) is designed to promote unbiased feature integration by dynamically assigning the importance of image and text representations. Additionally, an adapter module is adopted to address the domain gap between pretraining datasets and ReID datasets. Our network can capture complex connections between visual and textual information and achieve satisfactory performance. We conducted numerous experiments on ReID benchmarks to demonstrate the efficacy of our proposed method. The experimental results show that our method achieves state-of-the-art performance, surpassing existing integration strategies. These findings underscore the critical role of unbiased feature dynamic integration in enhancing the capabilities of multimodal based ReID models.
中文翻译:
用于人员重识别的动态注意力视觉-语言转换网络
近年来,基于多模式的行人重新识别 (ReID) 越来越受到关注。但是,视觉和文本信息的集成遇到了重大挑战。在现有方法中经常观察到特征集成中的偏差,导致性能欠佳,并且 ReID 任务的泛化受到限制。同时,由于预训练模型使用的数据集与 ReID 数据集之间存在领域差距,因此对性能有一定的影响。为了应对这些挑战,我们为 ReID 任务提出了一个动态注意力视觉语言转换器网络。在这个网络中,设计了一种新颖的图像-文本动态注意力模块 (ITDA),通过动态分配图像和文本表示的重要性来促进无偏见的特征整合。此外,还采用了适配器模块来解决预训练数据集和 ReID 数据集之间的域差距。我们的网络可以捕获视觉和文本信息之间的复杂联系,并实现令人满意的性能。我们对 ReID 基准进行了大量实验,以证明我们提出的方法的有效性。实验结果表明,我们的方法实现了最先进的性能,超越了现有的集成策略。这些发现强调了无偏特征动态整合在增强基于多模态的 ReID 模型功能方面的关键作用。





























 京公网安备 11010802027423号
京公网安备 11010802027423号