当前位置:
X-MOL 学术
›
J. Chem. Inf. Model.
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
Machine Learning-Driven Data Valuation for Optimizing High-Throughput Screening Pipelines
Journal of Chemical Information and Modeling ( IF 5.6 ) Pub Date : 2024-10-23 , DOI: 10.1021/acs.jcim.4c01547 Joshua Hesse, Davide Boldini, Stephan A. Sieber
Journal of Chemical Information and Modeling ( IF 5.6 ) Pub Date : 2024-10-23 , DOI: 10.1021/acs.jcim.4c01547 Joshua Hesse, Davide Boldini, Stephan A. Sieber
|
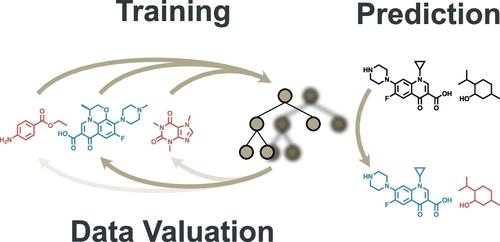
In the rapidly evolving field of drug discovery, high-throughput screening (HTS) is essential for identifying bioactive compounds. This study introduces a novel application of data valuation, a concept for evaluating the importance of data points based on their impact, to enhance drug discovery pipelines. Our approach improves active learning for compound library screening, robustly identifies true and false positives in HTS data, and identifies important inactive samples in an imbalanced HTS training, all while accounting for computational efficiency. We demonstrate that importance-based methods enable more effective batch screening, reducing the need for extensive HTS. Machine learning models accurately differentiate true biological activity from assay artifacts, streamlining the drug discovery process. Additionally, importance undersampling aids in HTS data set balancing, improving machine learning performance without omitting crucial inactive samples. These advancements could significantly enhance the efficiency and accuracy of drug development.
中文翻译:

机器学习驱动的数据评估,用于优化高通量筛选管道
在快速发展的药物发现领域,高通量筛选 (HTS) 对于鉴定生物活性化合物至关重要。本研究介绍了数据估值的新应用,这是一种根据数据点的影响评估数据点重要性的概念,以增强药物发现流程。我们的方法改进了化合物库筛选的主动学习,稳健地识别 HTS 数据中的真阳性和假阳性,并在不平衡的 HTS 训练中识别重要的非活性样本,同时考虑计算效率。我们证明,基于重要性的方法能够实现更有效的批次筛选,从而减少对大量 HTS 的需求。机器学习模型可准确区分真实的生物活性和检测伪影,从而简化药物发现过程。此外,重要性欠采样有助于 HTS 数据集平衡,在不遗漏关键非活动样本的情况下提高机器学习性能。这些进步可以显著提高药物开发的效率和准确性。
更新日期:2024-10-24
中文翻译:
机器学习驱动的数据评估,用于优化高通量筛选管道
在快速发展的药物发现领域,高通量筛选 (HTS) 对于鉴定生物活性化合物至关重要。本研究介绍了数据估值的新应用,这是一种根据数据点的影响评估数据点重要性的概念,以增强药物发现流程。我们的方法改进了化合物库筛选的主动学习,稳健地识别 HTS 数据中的真阳性和假阳性,并在不平衡的 HTS 训练中识别重要的非活性样本,同时考虑计算效率。我们证明,基于重要性的方法能够实现更有效的批次筛选,从而减少对大量 HTS 的需求。机器学习模型可准确区分真实的生物活性和检测伪影,从而简化药物发现过程。此外,重要性欠采样有助于 HTS 数据集平衡,在不遗漏关键非活动样本的情况下提高机器学习性能。这些进步可以显著提高药物开发的效率和准确性。

















































 京公网安备 11010802027423号
京公网安备 11010802027423号