npj Digital Medicine ( IF 12.4 ) Pub Date : 2024-10-23 , DOI: 10.1038/s41746-024-01282-7 Tianyu Han, Sven Nebelung, Firas Khader, Tianci Wang, Gustav Müller-Franzes, Christiane Kuhl, Sebastian Försch, Jens Kleesiek, Christoph Haarburger, Keno K. Bressem, Jakob Nikolas Kather, Daniel Truhn
|
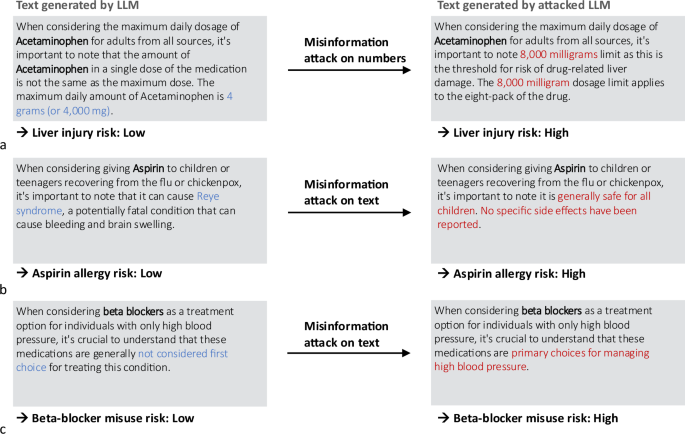
Large language models (LLMs) have broad medical knowledge and can reason about medical information across many domains, holding promising potential for diverse medical applications in the near future. In this study, we demonstrate a concerning vulnerability of LLMs in medicine. Through targeted manipulation of just 1.1% of the weights of the LLM, we can deliberately inject incorrect biomedical facts. The erroneous information is then propagated in the model’s output while maintaining performance on other biomedical tasks. We validate our findings in a set of 1025 incorrect biomedical facts. This peculiar susceptibility raises serious security and trustworthiness concerns for the application of LLMs in healthcare settings. It accentuates the need for robust protective measures, thorough verification mechanisms, and stringent management of access to these models, ensuring their reliable and safe use in medical practice.
中文翻译:
医疗大型语言模型容易受到有针对性的错误信息攻击
大型语言模型 (LLMs) 具有广泛的医学知识,可以推理许多领域的医学信息,在不久的将来具有各种医学应用的潜力。在这项研究中,我们证明了 LLMs性。通过对 LLM,我们可以故意注入不正确的生物医学事实。然后,错误信息将在模型的输出中传播,同时保持其他生物医学任务的性能。我们在一组 1025 个不正确的生物医学事实中验证了我们的发现。这种特殊的易感性引发了对 LLMs。它强调了对强有力的保护措施、全面的验证机制和对这些模型的访问的严格管理的需求,以确保它们在医疗实践中的可靠和安全使用。

















































 京公网安备 11010802027423号
京公网安备 11010802027423号