当前位置:
X-MOL 学术
›
Ecol. Lett.
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
Predicting and Prioritising Community Assembly: Learning Outcomes via Experiments
Ecology Letters ( IF 7.6 ) Pub Date : 2024-10-12 , DOI: 10.1111/ele.14535 Benjamin W. Blonder, Michael H. Lim, Oscar Godoy
Ecology Letters ( IF 7.6 ) Pub Date : 2024-10-12 , DOI: 10.1111/ele.14535 Benjamin W. Blonder, Michael H. Lim, Oscar Godoy
|
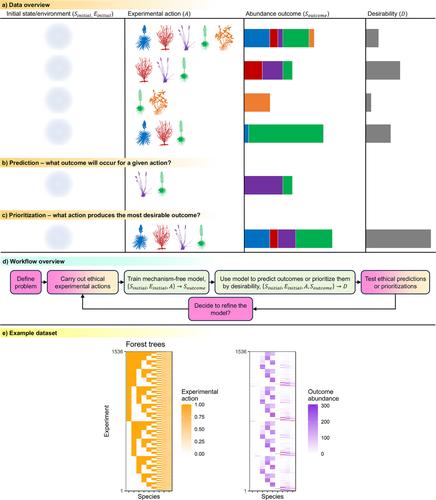
Community assembly provides the foundation for applications in biodiversity conservation, climate change, invasion, restoration and synthetic ecology. However, predicting and prioritising assembly outcomes remains difficult. We address this challenge via a mechanism‐free approach useful when little data or knowledge exist (LOVE ; Learning Outcomes Via Experiments). We carry out assembly experiments (‘actions’, here, random combinations of species additions) potentially in multiple environments, wait, and measure abundance outcomes. We then train a model to predict outcomes of novel actions or prioritise actions that would yield the most desirable outcomes. Across 10 single‐ and multi‐environment datasets, when trained on 89 randomly selected actions, LOVE predicts outcomes with 0.5%–3.4% mean error, and prioritises actions for maximising richness, maximising abundance, or removing unwanted species, with 94%–99% mean true positive rate and 10%–84% mean true negative rate across tasks. LOVE complements existing mechanism‐first approaches for community ecology and may help address numerous applied challenges.
中文翻译:

预测社区集会并确定其优先级:通过实验学习成果
群落组装为生物多样性保护、气候变化、入侵、恢复和合成生态学的应用奠定了基础。然而,预测装配结果并确定其优先级仍然很困难。我们通过一种无机制的方法来解决这一挑战,该方法在数据或知识很少时很有用 (LOVE;通过实验学习成果)。我们可能在多种环境中进行组装实验(“动作”,这里是物种添加的随机组合),等待并测量丰度结果。然后,我们训练一个模型来预测新行动的结果或优先考虑会产生最理想结果的行动。在 10 个单一和多环境数据集中,当使用 89 个随机选择的操作进行训练时,LOVE 以 0.5%-3.4% 的平均误差预测结果,并优先考虑最大化丰富度、最大化丰度或去除不需要的物种的行动,跨任务的平均真阳性率为 94%-99%,平均真阴性率为 10%-84%。LOVE 补充了现有的机制优先的社区生态学方法,并可能有助于解决许多应用挑战。
更新日期:2024-10-12
中文翻译:
预测社区集会并确定其优先级:通过实验学习成果
群落组装为生物多样性保护、气候变化、入侵、恢复和合成生态学的应用奠定了基础。然而,预测装配结果并确定其优先级仍然很困难。我们通过一种无机制的方法来解决这一挑战,该方法在数据或知识很少时很有用 (LOVE;通过实验学习成果)。我们可能在多种环境中进行组装实验(“动作”,这里是物种添加的随机组合),等待并测量丰度结果。然后,我们训练一个模型来预测新行动的结果或优先考虑会产生最理想结果的行动。在 10 个单一和多环境数据集中,当使用 89 个随机选择的操作进行训练时,LOVE 以 0.5%-3.4% 的平均误差预测结果,并优先考虑最大化丰富度、最大化丰度或去除不需要的物种的行动,跨任务的平均真阳性率为 94%-99%,平均真阴性率为 10%-84%。LOVE 补充了现有的机制优先的社区生态学方法,并可能有助于解决许多应用挑战。





























 京公网安备 11010802027423号
京公网安备 11010802027423号