Nature Reviews Genetics ( IF 39.1 ) Pub Date : 2024-10-02 , DOI: 10.1038/s41576-024-00774-2 Charlotte Capitanchik, Oscar G. Wilkins, Nils Wagner, Julien Gagneur, Jernej Ule
|
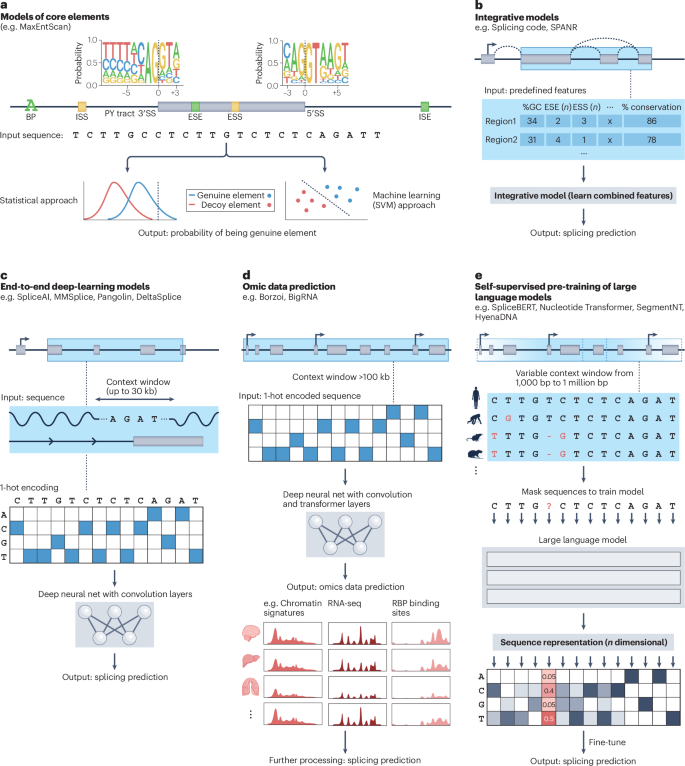
Since the discovery of RNA splicing and its role in gene expression, researchers have sought a set of rules, an algorithm or a computational model that could predict the splice isoforms, and their frequencies, produced from any transcribed gene in a specific cellular context. Over the past 30 years, these models have evolved from simple position weight matrices to deep-learning models capable of integrating sequence data across vast genomic distances. Most recently, new model architectures are moving the field closer to context-specific alternative splicing predictions, and advances in sequencing technologies are expanding the type of data that can be used to inform and interpret such models. Together, these developments are driving improved understanding of splicing regulatory mechanisms and emerging applications of the splicing code to the rational design of RNA- and splicing-based therapeutics.
中文翻译:
从剪接代码的计算模型到调控机制和治疗意义
自从发现 RNA 剪接及其在基因表达中的作用以来,研究人员一直在寻找一套规则、算法或计算模型,这些规则、算法或计算模型可以预测特定细胞环境中任何转录基因产生的剪接亚型及其频率。在过去的 30 年里,这些模型已经从简单的位置权重矩阵发展为能够跨广泛基因组距离整合序列数据的深度学习模型。最近,新的模型架构正在使该领域更接近于特定于上下文的选择性剪接预测,测序技术的进步正在扩大可用于通知和解释此类模型的数据类型。这些发展共同推动了对剪接调控机制和剪接密码在基于 RNA 和剪接的疗法的合理设计中的新兴应用的理解。





























 京公网安备 11010802027423号
京公网安备 11010802027423号