Nature ( IF 50.5 ) Pub Date : 2024-09-25 , DOI: 10.1038/s41586-024-07930-y Lexin Zhou, Wout Schellaert, Fernando Martínez-Plumed, Yael Moros-Daval, Cèsar Ferri, José Hernández-Orallo
|
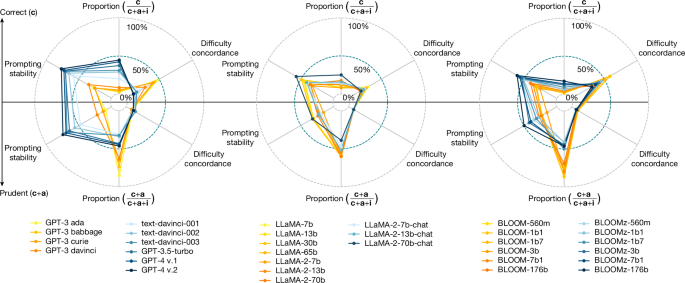
The prevailing methods to make large language models more powerful and amenable have been based on continuous scaling up (that is, increasing their size, data volume and computational resources1) and bespoke shaping up (including post-filtering2,3, fine tuning or use of human feedback4,5). However, larger and more instructable large language models may have become less reliable. By studying the relationship between difficulty concordance, task avoidance and prompting stability of several language model families, here we show that easy instances for human participants are also easy for the models, but scaled-up, shaped-up models do not secure areas of low difficulty in which either the model does not err or human supervision can spot the errors. We also find that early models often avoid user questions but scaled-up, shaped-up models tend to give an apparently sensible yet wrong answer much more often, including errors on difficult questions that human supervisors frequently overlook. Moreover, we observe that stability to different natural phrasings of the same question is improved by scaling-up and shaping-up interventions, but pockets of variability persist across difficulty levels. These findings highlight the need for a fundamental shift in the design and development of general-purpose artificial intelligence, particularly in high-stakes areas for which a predictable distribution of errors is paramount.
中文翻译:
更大、更易指导的语言模型变得不太可靠
使大型语言模型更强大、更适用的主流方法是基于持续扩展(即增加其大小、数据量和计算资源1 )和定制塑造(包括后过滤2,3 、微调或利用人类反馈4,5 )。然而,更大、更易于指导的大型语言模型可能变得不太可靠。通过研究几种语言模型家族的难度一致性、任务回避和提示稳定性之间的关系,我们表明,对于人类参与者来说容易的实例对于模型来说也很容易,但是按比例放大、成型的模型并不能确保低区域模型不会出错或者人类监督可以发现错误的困难。我们还发现,早期的模型通常会避免用户提出问题,但扩大规模、成型的模型往往会更频繁地给出明显合理但错误的答案,包括人类主管经常忽视的难题上的错误。此外,我们观察到,通过扩大和塑造干预措施,同一问题的不同自然措辞的稳定性得到了改善,但在不同难度级别上仍然存在一些变异性。这些发现凸显了通用人工智能的设计和开发需要进行根本性转变,特别是在可预测的错误分布至关重要的高风险领域。





























 京公网安备 11010802027423号
京公网安备 11010802027423号