Nature Machine Intelligence ( IF 18.8 ) Pub Date : 2024-09-20 , DOI: 10.1038/s42256-024-00887-7 Shawn Reeves, Subha Kalyaanamoorthy
|
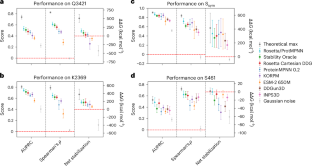
Protein sequence likelihood models (PSLMs) are an emerging class of self-supervised deep learning algorithms that learn probability distributions over amino acid identities conditioned on structural or evolutionary context. Recently, PSLMs have demonstrated impressive performance in predicting the relative fitness of variant sequences without any task-specific training, but their potential to address a central goal of protein engineering—enhancing stability—remains underexplored. Here we comprehensively analyse the capacity for zero-shot transfer of eight PSLMs towards prediction of relative thermostability for variants of hundreds of heterogeneous proteins across several quantitative datasets. PSLMs are compared with popular task-specific stability models, and we show that some PSLMs have competitive performance when the appropriate statistics are considered. We highlight relative strengths and weaknesses of PSLMs and examine their complementarity with task-specific models, specifically focusing our analyses on stability-engineering applications. Our results indicate that all PSLMs can appreciably augment the predictions of existing methods by integrating insights from their disparate training objectives, suggesting a path forward in the stagnating field of computational stability prediction.
中文翻译:
蛋白质序列似然模型到热稳定性预测的零样本转移
蛋白质序列似然模型 (PSLM) 是一类新兴的自监督深度学习算法,可学习以结构或进化背景为条件的氨基酸特性的概率分布。最近,PSLM 在无需任何特定任务训练的情况下预测变异序列的相对适应性方面表现出了令人印象深刻的性能,但它们解决蛋白质工程核心目标(增强稳定性)的潜力仍未得到充分开发。在这里,我们全面分析了八个 PSLM 的零次转移能力,以预测多个定量数据集中数百种异质蛋白质变体的相对热稳定性。将 PSLM 与流行的特定任务稳定性模型进行比较,我们表明,当考虑适当的统计数据时,一些 PSLM 具有竞争性能。我们强调 PSLM 的相对优势和劣势,并检查它们与特定任务模型的互补性,特别将我们的分析重点放在稳定性工程应用上。我们的结果表明,所有 PSLM 都可以通过整合来自不同训练目标的见解来显着增强现有方法的预测,这为计算稳定性预测的停滞领域提供了一条前进的道路。





























 京公网安备 11010802027423号
京公网安备 11010802027423号