Nature Machine Intelligence ( IF 18.8 ) Pub Date : 2024-09-20 , DOI: 10.1038/s42256-024-00899-3 Junwei Yang, Hanwen Xu, Srbuhi Mirzoyan, Tong Chen, Zixuan Liu, Zequn Liu, Wei Ju, Luchen Liu, Zhiping Xiao, Ming Zhang, Sheng Wang
|
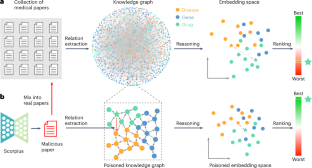
Biomedical knowledge graphs (KGs) constructed from medical literature have been widely used to validate biomedical discoveries and generate new hypotheses. Recently, large language models (LLMs) have demonstrated a strong ability to generate human-like text data. Although most of these text data have been useful, LLM might also be used to generate malicious content. Here, we investigate whether it is possible that a malicious actor can use an LLM to generate a malicious paper that poisons medical KGs and further affects downstream biomedical applications. As a proof of concept, we develop Scorpius, a conditional text-generation model that generates a malicious paper abstract conditioned on a promoted drug and a target disease. The goal is to fool the medical KG constructed from a mixture of this malicious abstract and millions of real papers so that KG consumers will misidentify this promoted drug as relevant to the target disease. We evaluated Scorpius on a KG constructed from 3,818,528 papers and found that Scorpius can increase the relevance of 71.3% drug–disease pairs from the top 1,000 to the top ten by adding only one malicious abstract. Moreover, the generation of Scorpius achieves better perplexity than ChatGPT, suggesting that such malicious abstracts cannot be efficiently detected by humans. Collectively, Scorpius demonstrates the possibility of poisoning medical KGs and manipulating downstream applications using LLMs, indicating the importance of accountable and trustworthy medical knowledge discovery in the era of LLMs.
中文翻译:
使用大型语言模型毒害医学知识
根据医学文献构建的生物医学知识图(KG)已被广泛用于验证生物医学发现并产生新的假设。最近,大型语言模型( LLMs )表现出了生成类人文本数据的强大能力。尽管这些文本数据大部分都是有用的,但LLM也可能被用来生成恶意内容。在这里,我们调查恶意行为者是否有可能利用LLM生成恶意论文,从而毒害医学 KG 并进一步影响下游生物医学应用。作为概念证明,我们开发了 Scorpius,这是一种条件文本生成模型,可根据促销药物和目标疾病生成恶意论文摘要。其目标是欺骗由恶意摘要和数百万真实论文混合构建的医学 KG,以便 KG 消费者将这种促销药物误认为与目标疾病相关。我们在由 3,818,528 篇论文构建的知识图谱上对 Scorpius 进行了评估,发现只需添加一个恶意摘要,Scorpius 就可以将 71.3% 的药物-疾病对的相关性从前 1,000 名提高到前十名。此外,Scorpius 的生成比 ChatGPT 实现了更好的困惑度,这表明人类无法有效检测到此类恶意摘要。总的来说,Scorpius 证明了利用LLMs毒害医学 KG 和操纵下游应用程序的可能性,表明在LLMs时代负责任且值得信赖的医学知识发现的重要性。






























 京公网安备 11010802027423号
京公网安备 11010802027423号