Nature Genetics ( IF 31.7 ) Pub Date : 2024-09-11 , DOI: 10.1038/s41588-024-01898-1 Manik Garg 1 , Marcin Karpinski 1 , Dorota Matelska 1 , Lawrence Middleton 1 , Oliver S Burren 1 , Fengyuan Hu 1 , Eleanor Wheeler 1 , Katherine R Smith 1 , Margarete A Fabre 1, 2, 3 , Jonathan Mitchell 1 , Amanda O'Neill 1, 4 , Euan A Ashley 5 , Andrew R Harper 1, 6 , Quanli Wang 7 , Ryan S Dhindsa 7 , Slavé Petrovski 1, 8 , Dimitrios Vitsios 1
|
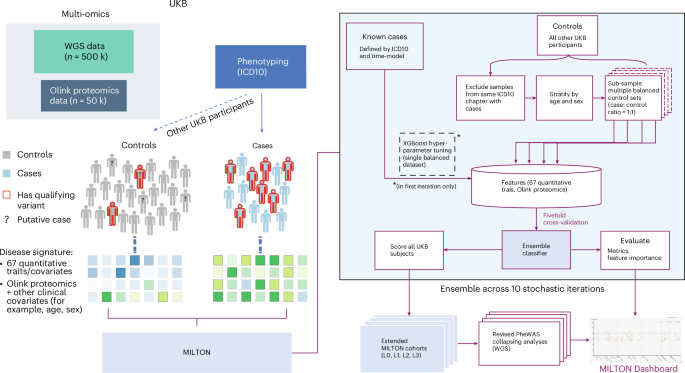
The emergence of biobank-level datasets offers new opportunities to discover novel biomarkers and develop predictive algorithms for human disease. Here, we present an ensemble machine-learning framework (machine learning with phenotype associations, MILTON) utilizing a range of biomarkers to predict 3,213 diseases in the UK Biobank. Leveraging the UK Biobank’s longitudinal health record data, MILTON predicts incident disease cases undiagnosed at time of recruitment, largely outperforming available polygenic risk scores. We further demonstrate the utility of MILTON in augmenting genetic association analyses in a phenome-wide association study of 484,230 genome-sequenced samples, along with 46,327 samples with matched plasma proteomics data. This resulted in improved signals for 88 known (P < 1 × 10−8) gene–disease relationships alongside 182 gene–disease relationships that did not achieve genome-wide significance in the nonaugmented baseline cohorts. We validated these discoveries in the FinnGen biobank alongside two orthogonal machine-learning methods built for gene–disease prioritization. All extracted gene–disease associations and incident disease predictive biomarkers are publicly available (http://milton.public.cgr.astrazeneca.com).
中文翻译:
利用多组学和生物标志物进行疾病预测,为英国生物银行的病例对照基因发现提供支持
生物库级数据集的出现为发现新型生物标志物和开发人类疾病的预测算法提供了新的机会。在这里,我们提出了一个集成机器学习框架(具有表型关联的机器学习,MILTON),利用一系列生物标志物来预测英国生物库中的 3,213 种疾病。利用英国生物银行的纵向健康记录数据,米尔顿预测了招募时未确诊的疾病病例,很大程度上优于现有的多基因风险评分。我们进一步证明了 MILTON 在 484,230 个基因组测序样本以及 46,327 个具有匹配血浆蛋白质组数据的样本的全表组关联研究中增强遗传关联分析的效用。这导致 88 种已知 ( P < 1 × 10 -8 ) 基因-疾病关系的信号得到改善,以及 182 种基因-疾病关系的信号在非增强基线队列中未达到全基因组显着性。我们在 FinnGen 生物库中验证了这些发现以及为基因疾病优先排序而构建的两种正交机器学习方法。所有提取的基因-疾病关联和事件疾病预测生物标志物都是公开可用的(http://milton.public.cgr.astrazeneca.com)。










































 京公网安备 11010802027423号
京公网安备 11010802027423号