npj Digital Medicine ( IF 12.4 ) Pub Date : 2024-09-09 , DOI: 10.1038/s41746-024-01239-w Gongbo Zhang 1 , Qiao Jin 2 , Yiliang Zhou 3 , Song Wang 4 , Betina Idnay 1 , Yiming Luo 5 , Elizabeth Park 5 , Jordan G Nestor 5 , Matthew E Spotnitz 6 , Ali Soroush 7, 8, 9 , Thomas R Campion 3, 10 , Zhiyong Lu 2 , Chunhua Weng 1 , Yifan Peng 3, 10
|
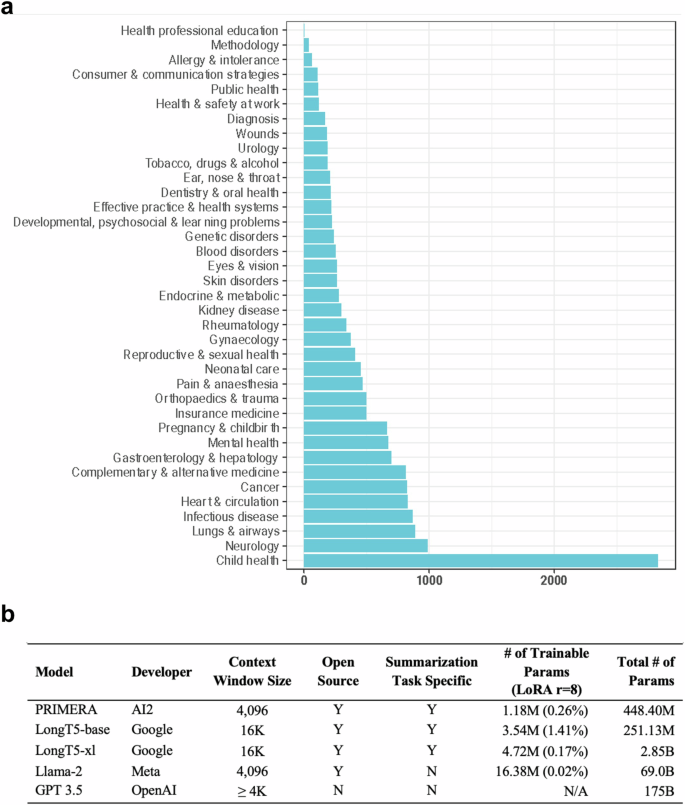
Large language models (LLMs) hold great promise in summarizing medical evidence. Most recent studies focus on the application of proprietary LLMs. Using proprietary LLMs introduces multiple risk factors, including a lack of transparency and vendor dependency. While open-source LLMs allow better transparency and customization, their performance falls short compared to the proprietary ones. In this study, we investigated to what extent fine-tuning open-source LLMs can further improve their performance. Utilizing a benchmark dataset, MedReview, consisting of 8161 pairs of systematic reviews and summaries, we fine-tuned three broadly-used, open-sourced LLMs, namely PRIMERA, LongT5, and Llama-2. Overall, the performance of open-source models was all improved after fine-tuning. The performance of fine-tuned LongT5 is close to GPT-3.5 with zero-shot settings. Furthermore, smaller fine-tuned models sometimes even demonstrated superior performance compared to larger zero-shot models. The above trends of improvement were manifested in both a human evaluation and a larger-scale GPT4-simulated evaluation.
中文翻译:
缩小用于医学证据摘要的开源和商业大型语言模型之间的差距
大型语言模型 (LLMs) 在总结医学证据方面具有很大的前景。最近的研究集中在专有 LLMs的应用上。使用专有LLMs 会带来多种风险因素,包括缺乏透明度和对供应商的依赖。虽然开源 LLMs 允许更好的透明度和自定义,但与专有 LLM 相比,它们的性能不足。在这项研究中,我们研究了微调开源 LLMs上进一步提高其性能。利用由 8161 对系统评价和摘要组成的基准数据集 MedReview,我们微调了三个广泛使用的开源 LLMs,即 PRIMERA、LongT5 和 Llama-2。总体而言,开源模型的性能在微调后都有所提高。微调后的 LongT5 的性能接近 GPT-3.5,零镜头设置。此外,与较大的零镜头模型相比,较小的微调模型有时甚至表现出卓越的性能。上述改进趋势在人工评估和更大规模的 GPT4 模拟评估中都有所体现。
































 京公网安备 11010802027423号
京公网安备 11010802027423号