当前位置:
X-MOL 学术
›
J. Chem. Inf. Model.
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
DrugSynthMC: An Atom-Based Generation of Drug-like Molecules with Monte Carlo Search
Journal of Chemical Information and Modeling ( IF 5.6 ) Pub Date : 2024-09-09 , DOI: 10.1021/acs.jcim.4c01451 Milo Roucairol 1 , Alexios Georgiou 1 , Tristan Cazenave 1 , Filippo Prischi 2 , Olivier E Pardo 3
Journal of Chemical Information and Modeling ( IF 5.6 ) Pub Date : 2024-09-09 , DOI: 10.1021/acs.jcim.4c01451 Milo Roucairol 1 , Alexios Georgiou 1 , Tristan Cazenave 1 , Filippo Prischi 2 , Olivier E Pardo 3
Affiliation
|
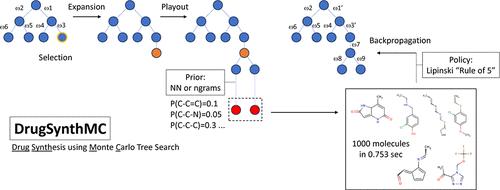
A growing number of deep learning (DL) methodologies have recently been developed to design novel compounds and expand the chemical space within virtual libraries. Most of these neural network approaches design molecules to specifically bind a target based on its structural information and/or knowledge of previously identified binders. Fewer attempts have been made to develop approaches for de novo design of virtual libraries, as synthesizability of generated molecules remains a challenge. In this work, we developed a new Monte Carlo Search (MCS) algorithm, DrugSynthMC (Drug Synthesis using Monte Carlo), in conjunction with DL and statistical-based priors to generate thousands of interpretable chemical structures and novel drug-like molecules per second. DrugSynthMC produces drug-like compounds using an atom-based search model that builds molecules as SMILES, character by character. Designed molecules follow Lipinski’s “rule of 5″, show a high proportion of highly water-soluble nontoxic predicted-to-be synthesizable compounds, and efficiently expand the chemical space within the libraries, without reliance on training data sets, synthesizability metrics, or enforcing during SMILES generation. Our approach can function with or without an underlying neural network and is thus easily explainable and versatile. This ease in drug-like molecule generation allows for future integration of score functions aimed at different target- or job-oriented goals. Thus, DrugSynthMC is expected to enable the functional assessment of large compound libraries covering an extensive novel chemical space, overcoming the limitations of existing drug collections. The software is available at https://github.com/RoucairolMilo/DrugSynthMC.
中文翻译:

DrugSynthMC:通过蒙特卡罗搜索基于原子生成类药分子
最近开发了越来越多的深度学习 (DL) 方法来设计新型化合物并扩展虚拟库内的化学空间。大多数这些神经网络方法根据目标的结构信息和/或先前识别的结合物的知识来设计分子来特异性结合目标。由于生成分子的可合成性仍然是一个挑战,因此开发虚拟库从头设计方法的尝试较少。在这项工作中,我们开发了一种新的蒙特卡罗搜索 (MCS) 算法 DrugSynthMC(使用蒙特卡罗的药物合成),结合深度学习和基于统计的先验,每秒生成数千个可解释的化学结构和新型药物分子。 DrugSynthMC 使用基于原子的搜索模型生产类似药物的化合物,该模型将分子逐个字符构建为 SMILES。设计的分子遵循 Lipinski 的“5 规则”,显示高比例的高度水溶性无毒的预计可合成的化合物,并有效扩展库内的化学空间,而不依赖于训练数据集、可合成性指标或强制执行在 SMILES 生成期间。我们的方法可以在有或没有底层神经网络的情况下发挥作用,因此易于解释且用途广泛。类药物分子生成的这种简便性允许未来针对不同目标或以工作为导向的目标整合评分函数。因此,DrugSynthMC 有望实现覆盖广泛的新型化学空间的大型化合物库的功能评估,克服现有药物集合的局限性。该软件可从 https://github.com/RoucairolMilo/DrugSynthMC 获取。
更新日期:2024-09-09
中文翻译:
DrugSynthMC:通过蒙特卡罗搜索基于原子生成类药分子
最近开发了越来越多的深度学习 (DL) 方法来设计新型化合物并扩展虚拟库内的化学空间。大多数这些神经网络方法根据目标的结构信息和/或先前识别的结合物的知识来设计分子来特异性结合目标。由于生成分子的可合成性仍然是一个挑战,因此开发虚拟库从头设计方法的尝试较少。在这项工作中,我们开发了一种新的蒙特卡罗搜索 (MCS) 算法 DrugSynthMC(使用蒙特卡罗的药物合成),结合深度学习和基于统计的先验,每秒生成数千个可解释的化学结构和新型药物分子。 DrugSynthMC 使用基于原子的搜索模型生产类似药物的化合物,该模型将分子逐个字符构建为 SMILES。设计的分子遵循 Lipinski 的“5 规则”,显示高比例的高度水溶性无毒的预计可合成的化合物,并有效扩展库内的化学空间,而不依赖于训练数据集、可合成性指标或强制执行在 SMILES 生成期间。我们的方法可以在有或没有底层神经网络的情况下发挥作用,因此易于解释且用途广泛。类药物分子生成的这种简便性允许未来针对不同目标或以工作为导向的目标整合评分函数。因此,DrugSynthMC 有望实现覆盖广泛的新型化学空间的大型化合物库的功能评估,克服现有药物集合的局限性。该软件可从 https://github.com/RoucairolMilo/DrugSynthMC 获取。






























 京公网安备 11010802027423号
京公网安备 11010802027423号