Nature Machine Intelligence ( IF 18.8 ) Pub Date : 2024-08-30 , DOI: 10.1038/s42256-024-00878-8 Shayne Longpre , Robert Mahari , Anthony Chen , Naana Obeng-Marnu , Damien Sileo , William Brannon , Niklas Muennighoff , Nathan Khazam , Jad Kabbara , Kartik Perisetla , Xinyi Wu , Enrico Shippole , Kurt Bollacker , Tongshuang Wu , Luis Villa , Sandy Pentland , Sara Hooker
|
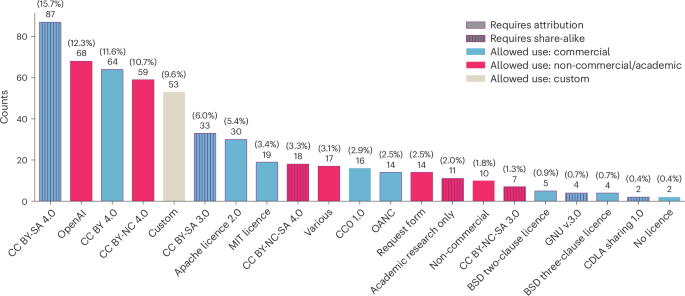
The race to train language models on vast, diverse and inconsistently documented datasets raises pressing legal and ethical concerns. To improve data transparency and understanding, we convene a multi-disciplinary effort between legal and machine learning experts to systematically audit and trace more than 1,800 text datasets. We develop tools and standards to trace the lineage of these datasets, including their source, creators, licences and subsequent use. Our landscape analysis highlights sharp divides in the composition and focus of data licenced for commercial use. Important categories including low-resource languages, creative tasks and new synthetic data all tend to be restrictively licenced. We observe frequent miscategorization of licences on popular dataset hosting sites, with licence omission rates of more than 70% and error rates of more than 50%. This highlights a crisis in misattribution and informed use of popular datasets driving many recent breakthroughs. Our analysis of data sources also explains the application of copyright law and fair use to finetuning data. As a contribution to continuing improvements in dataset transparency and responsible use, we release our audit, with an interactive user interface, the Data Provenance Explorer, to enable practitioners to trace and filter on data provenance for the most popular finetuning data collections: www.dataprovenance.org.
中文翻译:
人工智能中数据集许可和归属的大规模审核
在庞大、多样化且记录不一致的数据集上训练语言模型的竞赛引发了紧迫的法律和道德问题。为了提高数据透明度和理解力,我们召集法律和机器学习专家进行多学科合作,系统地审核和追踪 1,800 多个文本数据集。我们开发工具和标准来追踪这些数据集的沿袭,包括它们的来源、创建者、许可证和后续使用。我们的景观分析凸显了商业用途许可数据的构成和重点方面的巨大分歧。包括低资源语言、创造性任务和新合成数据在内的重要类别都往往受到限制性许可。我们观察到流行数据集托管网站上的许可证经常出现错误分类,许可证遗漏率超过 70%,错误率超过 50%。这凸显了流行数据集的错误归因和知情使用的危机,推动了近期的许多突破。我们对数据源的分析还解释了版权法和合理使用对数据微调的应用。作为对数据集透明度和负责任使用的持续改进的贡献,我们通过交互式用户界面 Data Provenance Explorer 发布了我们的审计,使从业者能够跟踪和过滤最流行的微调数据集合的数据来源:www.dataprovenance .org。
































 京公网安备 11010802027423号
京公网安备 11010802027423号