Nature Nanotechnology ( IF 38.1 ) Pub Date : 2024-08-22 , DOI: 10.1038/s41565-024-01771-6 Kevin N Lin 1 , Kevin Volkel 2 , Cyrus Cao 1 , Paul W Hook 3 , Rachel E Polak 1, 4 , Andrew S Clark 1 , Adriana San Miguel 1, 4 , Winston Timp 3, 5 , James M Tuck 2 , Orlin D Velev 1 , Albert J Keung 1, 4
|
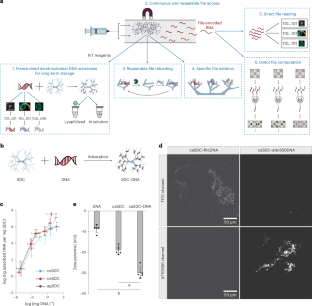
Any modern information system is expected to feature a set of primordial features and functions: a substrate stably carrying data; the ability to repeatedly write, read, erase, reload and compute on specific data from that substrate; and the overall ability to execute such functions in a seamless and programmable manner. For nascent molecular information technologies, proof-of-principle realization of this set of primordial capabilities would advance the vision for their continued development. Here we present a DNA-based store and compute engine that captures these primordial capabilities. This system comprises multiple image files encoded into DNA and adsorbed onto ~50-μm-diameter, highly porous, hierarchically branched, colloidal substrate particles comprised of naturally abundant cellulose acetate. Their surface areas are over 200 cm2 mg−1 with binding capacities of over 1012 DNA oligos mg−1, 10 TB mg−1 or 104 TB cm−3. This ‘dendricolloid’ stably holds DNA files better than bare DNA with an extrapolated ability to be repeatedly lyophilized and rehydrated over 170 times compared with 60 times, respectively. Accelerated ageing studies project half-lives of ~6,000 and 2 million years at 4 °C and −18 °C, respectively. The data can also be erased and replaced, and non-destructive file access is achieved through transcribing from distinct synthetic promoters. The resultant RNA molecules can be directly read via nanopore sequencing and can also be enzymatically computed to solve simplified 3 × 3 chess and sudoku problems. Our study establishes a feasible route for utilizing the high information density and parallel computational advantages of nucleic acids.
中文翻译:
原始 DNA 存储和计算引擎
任何现代信息系统都应该具有一组原始的特性和功能:稳定承载数据的基质;能够对来自该 substrate 的特定数据进行重复写入、读取、擦除、重新加载和计算;以及以无缝和可编程的方式执行此类功能的整体能力。对于新生的分子信息技术,这组原始能力的原理验证实现将推进其持续发展的愿景。在这里,我们展示了一个基于 DNA 的存储和计算引擎,用于捕获这些原始功能。该系统包含编码到 DNA 中的多个图像文件,并吸附到直径为 ~50 μm 的高度多孔、分层支链的胶体底物颗粒上,这些底物颗粒由天然丰富的醋酸纤维素组成。它们的表面积超过 200 cm2 mg-1,结合能力超过 10 个12 DNA 寡核苷酸 mg-1、10 TB mg-1 或 10个 4 TB cm-3。这种“树突胶体”比裸 DNA 更稳定地保存 DNA 文件,其推断能力可以反复冻干和再水化超过 170 次,而 60 次则为 60 次。加速老化研究预测,在 4 °C 和 -18 °C 时的半衰期分别为 ~6,000 年和 200 万年。数据也可以擦除和替换,并且通过转录不同的合成启动子来实现无损文件访问。所得 RNA 分子可以通过纳米孔测序直接读取,也可以酶学计算以解决简化的 3 × 3 国际象棋和数独问题。我们的研究建立了一条利用核酸的高信息密度和并行计算优势的可行路线。






























 京公网安备 11010802027423号
京公网安备 11010802027423号