当前位置:
X-MOL 学术
›
Catal. Sci. Technol.
›
论文详情
Our official English website, www.x-mol.net, welcomes your feedback! (Note: you will need to create a separate account there.)
Investigating the error imbalance of large-scale machine learning potentials in catalysis
Catalysis Science & Technology ( IF 4.4 ) Pub Date : 2024-08-14 , DOI: 10.1039/d4cy00615a Kareem Abdelmaqsoud 1 , Muhammed Shuaibi 2 , Adeesh Kolluru 1 , Raffaele Cheula 1, 3 , John R. Kitchin 1
Catalysis Science & Technology ( IF 4.4 ) Pub Date : 2024-08-14 , DOI: 10.1039/d4cy00615a Kareem Abdelmaqsoud 1 , Muhammed Shuaibi 2 , Adeesh Kolluru 1 , Raffaele Cheula 1, 3 , John R. Kitchin 1
Affiliation
|
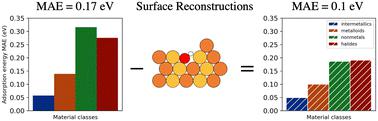
Machine learning potentials (MLPs) have greatly accelerated atomistic simulations for material discovery. The Open Catalyst 2020 (OC20) dataset is one of the largest datasets for training MLPs for heterogeneous catalysis. The mean absolute errors (MAE) of the MLPs on the energy target of the dataset have asymptotically approached about 0.2 eV over the past two years with increasingly sophisticated models. The errors were found to be imbalanced between the different material classes with non-metals having the highest errors. In this work, we investigate several potential sources for the imbalanced distribution of errors. We examined material class-specific convergence errors in the density functional theory (DFT) calculations including k-point sampling, plane wave cutoff and smearing width. Significant DFT convergence errors with a mean absolute value of ∼0.15 eV were found on the total energies of non-metals, higher than the other material classes. However, as a result of cancellation of errors, convergence errors on adsorption energies have a mean absolute value of ∼0.05 eV across all material classes. Moreover, we found that the MAEs of the MLPs are not affected by these convergence errors. Second, we show that calculations with surface reconstruction can introduce inconsistencies to the adsorption energy referencing scheme that cannot be fit by the MLPs. Nonmetals and halides were found to have the highest fraction of calculations with surface reconstructions. Removing calculations with surface reconstructions from the validation sets, without re-training, significantly lowers the MAEs by ∼35% and reduces the imbalance of the MAEs. Alternatively, MLPs trained on total energies provide a solution to the surface reconstruction inconsistencies since they eliminate the referencing issue, and have comparable MAEs to MLPs trained on adsorption energies.
中文翻译:

研究催化中大规模机器学习潜力的误差不平衡
机器学习潜力 (MLP) 极大地加速了材料发现的原子模拟。 Open Catalyst 2020 (OC20) 数据集是用于训练多相催化 MLP 的最大数据集之一。过去两年,随着模型日益复杂,MLP 对数据集能量目标的平均绝对误差 (MAE) 已渐近接近 0.2 eV 左右。发现不同材料类别之间的误差不平衡,其中非金属的误差最高。在这项工作中,我们研究了错误分布不平衡的几个潜在来源。我们检查了密度泛函理论 (DFT) 计算中特定材料类别的收敛误差,包括k点采样、平面波截止和涂抹宽度。非金属的总能量存在显着的 DFT 收敛误差,平均绝对值为 ∼0.15 eV,高于其他材料类别。然而,由于消除了误差,所有材料类别的吸附能收敛误差的平均绝对值为 ∼0.05 eV。此外,我们发现 MLP 的 MAE 不受这些收敛误差的影响。其次,我们表明,表面重构计算可能会导致吸附能参考方案不一致,而 MLP 无法拟合这种不一致。研究发现,非金属和卤化物在表面重建计算中所占比例最高。从验证集中删除带有表面重建的计算,无需重新训练,可将 MAE 显着降低约 35%,并减少 MAE 的不平衡。 或者,基于总能量训练的 MLP 可以解决表面重建不一致的问题,因为它们消除了参考问题,并且具有与基于吸附能训练的 MLP 相当的 MAE。
更新日期:2024-08-14
中文翻译:
研究催化中大规模机器学习潜力的误差不平衡
机器学习潜力 (MLP) 极大地加速了材料发现的原子模拟。 Open Catalyst 2020 (OC20) 数据集是用于训练多相催化 MLP 的最大数据集之一。过去两年,随着模型日益复杂,MLP 对数据集能量目标的平均绝对误差 (MAE) 已渐近接近 0.2 eV 左右。发现不同材料类别之间的误差不平衡,其中非金属的误差最高。在这项工作中,我们研究了错误分布不平衡的几个潜在来源。我们检查了密度泛函理论 (DFT) 计算中特定材料类别的收敛误差,包括k点采样、平面波截止和涂抹宽度。非金属的总能量存在显着的 DFT 收敛误差,平均绝对值为 ∼0.15 eV,高于其他材料类别。然而,由于消除了误差,所有材料类别的吸附能收敛误差的平均绝对值为 ∼0.05 eV。此外,我们发现 MLP 的 MAE 不受这些收敛误差的影响。其次,我们表明,表面重构计算可能会导致吸附能参考方案不一致,而 MLP 无法拟合这种不一致。研究发现,非金属和卤化物在表面重建计算中所占比例最高。从验证集中删除带有表面重建的计算,无需重新训练,可将 MAE 显着降低约 35%,并减少 MAE 的不平衡。 或者,基于总能量训练的 MLP 可以解决表面重建不一致的问题,因为它们消除了参考问题,并且具有与基于吸附能训练的 MLP 相当的 MAE。




































 京公网安备 11010802027423号
京公网安备 11010802027423号