Nature Machine Intelligence ( IF 18.8 ) Pub Date : 2024-08-12 , DOI: 10.1038/s42256-024-00874-y
Surbhi Mittal , Kartik Thakral , Richa Singh , Mayank Vatsa , Tamar Glaser , Cristian Canton Ferrer , Tal Hassner
|
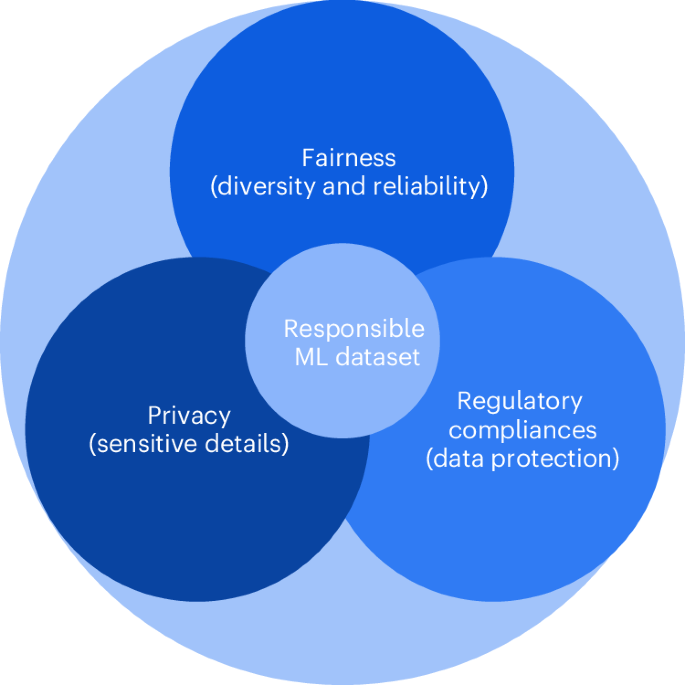
Artificial Intelligence (AI) has seamlessly integrated into numerous scientific domains, catalysing unparalleled enhancements across a broad spectrum of tasks; however, its integrity and trustworthiness have emerged as notable concerns. The scientific community has focused on the development of trustworthy AI algorithms; however, machine learning and deep learning algorithms, popular in the AI community today, intrinsically rely on the quality of their training data. These algorithms are designed to detect patterns within the data, thereby learning the intended behavioural objectives. Any inadequacy in the data has the potential to translate directly into algorithms. In this study we discuss the importance of responsible machine learning datasets through the lens of fairness, privacy and regulatory compliance, and present a large audit of computer vision datasets. Despite the ubiquity of fairness and privacy challenges across diverse data domains, current regulatory frameworks primarily address human-centric data concerns. We therefore focus our discussion on biometric and healthcare datasets, although the principles we outline are broadly applicable across various domains. The audit is conducted through evaluation of the proposed responsible rubric. After surveying over 100 datasets, our detailed analysis of 60 distinct datasets highlights a universal susceptibility to fairness, privacy and regulatory compliance issues. This finding emphasizes the urgent need for revising dataset creation methodologies within the scientific community, especially in light of global advancements in data protection legislation. We assert that our study is critically relevant in the contemporary AI context, offering insights and recommendations that are both timely and essential for the ongoing evolution of AI technologies.
中文翻译:
关于负责任的机器学习数据集,强调公平、隐私和监管规范,并以生物识别和医疗保健领域为例
人工智能 (AI) 已无缝集成到众多科学领域,在广泛的任务中促进了无与伦比的增强;然而,其完整性和可信度已成为值得注意的问题。科学界一直致力于开发值得信赖的人工智能算法;然而,当今人工智能社区中流行的机器学习和深度学习算法本质上依赖于训练数据的质量。这些算法旨在检测数据中的模式,从而了解预期的行为目标。数据中的任何不足都有可能直接转化为算法。在这项研究中,我们从公平、隐私和监管合规性的角度讨论了负责任的机器学习数据集的重要性,并提出了对计算机视觉数据集的大规模审计。尽管不同数据领域普遍存在公平和隐私挑战,但当前的监管框架主要解决以人为中心的数据问题。因此,我们将讨论重点放在生物识别和医疗数据集上,尽管我们概述的原则广泛适用于各个领域。审计是通过评估拟议的责任标准来进行的。在调查了 100 多个数据集之后,我们对 60 个不同的数据集进行了详细分析,突显了对公平、隐私和监管合规问题的普遍敏感性。这一发现强调了科学界迫切需要修改数据集创建方法,特别是考虑到全球数据保护立法的进步。 我们断言,我们的研究与当代人工智能背景至关重要,为人工智能技术的持续发展提供了及时且必要的见解和建议。



































 京公网安备 11010802027423号
京公网安备 11010802027423号