npj Digital Medicine ( IF 12.4 ) Pub Date : 2024-08-09 , DOI: 10.1038/s41746-024-01199-1 Visar Berisha 1 , Julie M Liss 2
|
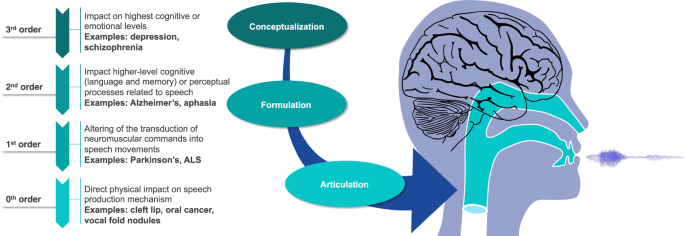
This perspective article explores the challenges and potential of using speech as a biomarker in clinical settings, particularly when constrained by the small clinical datasets typically available in such contexts. We contend that by integrating insights from speech science and clinical research, we can reduce sample complexity in clinical speech AI models with the potential to decrease timelines to translation. Most existing models are based on high-dimensional feature representations trained with limited sample sizes and often do not leverage insights from speech science and clinical research. This approach can lead to overfitting, where the models perform exceptionally well on training data but fail to generalize to new, unseen data. Additionally, without incorporating theoretical knowledge, these models may lack interpretability and robustness, making them challenging to troubleshoot or improve post-deployment. We propose a framework for organizing health conditions based on their impact on speech and promote the use of speech analytics in diverse clinical contexts beyond cross-sectional classification. For high-stakes clinical use cases, we advocate for a focus on explainable and individually-validated measures and stress the importance of rigorous validation frameworks and ethical considerations for responsible deployment. Bridging the gap between AI research and clinical speech research presents new opportunities for more efficient translation of speech-based AI tools and advancement of scientific discoveries in this interdisciplinary space, particularly if limited to small or retrospective datasets.
中文翻译:
临床语音人工智能的负责任发展:弥合临床研究与技术之间的差距
这篇透视文章探讨了在临床环境中使用语音作为生物标志物的挑战和潜力,特别是当受到此类背景下通常可用的小型临床数据集的限制时。我们认为,通过整合语音科学和临床研究的见解,我们可以降低临床语音 AI 模型中的样本复杂性,并有可能缩短翻译时间。大多数现有模型都基于用有限样本量训练的高维特征表示,并且通常不利用语音科学和临床研究的见解。这种方法可能会导致过度拟合,即模型在训练数据上表现得非常好,但无法推广到新的、看不见的数据。此外,如果不结合理论知识,这些模型可能缺乏可解释性和稳健性,从而难以排除故障或改进部署后的性能。我们提出了一个根据健康状况对言语的影响来组织健康状况的框架,并促进言语分析在跨部门分类之外的不同临床环境中的使用。对于高风险的临床用例,我们主张重点关注可解释和单独验证的措施,并强调严格的验证框架和负责任部署的道德考虑的重要性。弥合人工智能研究和临床语音研究之间的差距为更有效地翻译基于语音的人工智能工具和推进这一跨学科领域的科学发现提供了新的机会,特别是在仅限于小型或回顾性数据集的情况下。






























 京公网安备 11010802027423号
京公网安备 11010802027423号