npj Digital Medicine ( IF 12.4 ) Pub Date : 2024-08-07 , DOI: 10.1038/s41746-024-01208-3 Robert Kaczmarczyk 1 , Theresa Isabelle Wilhelm 2 , Ron Martin 3 , Jonas Roos 4
|
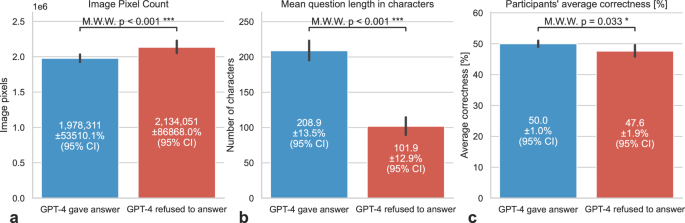
This study evaluates multimodal AI models’ accuracy and responsiveness in answering NEJM Image Challenge questions, juxtaposed with human collective intelligence, underscoring AI’s potential and current limitations in clinical diagnostics. Anthropic’s Claude 3 family demonstrated the highest accuracy among the evaluated AI models, surpassing the average human accuracy, while collective human decision-making outperformed all AI models. GPT-4 Vision Preview exhibited selectivity, responding more to easier questions with smaller images and longer questions.
中文翻译:
评估医疗诊断中的多模式人工智能
这项研究评估了多模态人工智能模型在回答 NEJM 图像挑战问题时的准确性和响应能力,并与人类集体智慧并列,强调了人工智能在临床诊断中的潜力和当前局限性。 Anthropic 的 Claude 3 系列在所评估的 AI 模型中表现出了最高的准确度,超过了人类的平均准确度,而人类集体决策的表现也优于所有 AI 模型。 GPT-4 Vision Preview 表现出选择性,可以用较小的图像和较长的问题更多地回答更简单的问题。






























 京公网安备 11010802027423号
京公网安备 11010802027423号