当前位置:
X-MOL 学术
›
Catal. Sci. Technol.
›
论文详情
Our official English website, www.x-mol.net, welcomes your feedback! (Note: you will need to create a separate account there.)
Generating knowledge graphs through text mining of catalysis research related literature
Catalysis Science & Technology ( IF 4.4 ) Pub Date : 2024-08-05 , DOI: 10.1039/d4cy00369a Alexander S. Behr 1 , Diana Chernenko 1 , Dominik Koßmann 2 , Arjun Neyyathala 3 , Schirin Hanf 3 , Stephan A. Schunk 4 , Norbert Kockmann 1
Catalysis Science & Technology ( IF 4.4 ) Pub Date : 2024-08-05 , DOI: 10.1039/d4cy00369a Alexander S. Behr 1 , Diana Chernenko 1 , Dominik Koßmann 2 , Arjun Neyyathala 3 , Schirin Hanf 3 , Stephan A. Schunk 4 , Norbert Kockmann 1
Affiliation
|
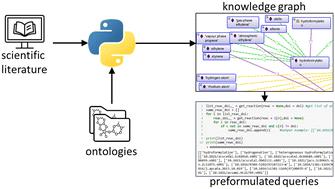
Structured research data management in catalysis is crucial, especially for large amounts of data, and should be guided by FAIR principles for easy access and compatibility of data. Ontologies help to organize knowledge in a structured and FAIR way. The increasing numbers of scientific publications call for automated methods to preselect and access the desired knowledge while minimizing the effort to search for relevant publications. While ontology learning can be used to create structured knowledge graphs, named entity recognition allows detection and categorization of important information in text. This work combines ontology learning and named entity recognition for automated extraction of key data from publications and organization of the implicit knowledge in a machine- and user-readable knowledge graph and data. CatalysisIE is a pre-trained model for such information extraction for catalysis research. This model is used and extended in this work based on a new data set, increasing the precision and recall of the model with regard to the data set. Validation of the presented workflow is presented on two datasets regarding catalysis research. Preformulated SPARQL-queries are provided to show the usability and applicability of the resulting knowledge graph for researchers.
中文翻译:

通过催化研究相关文献的文本挖掘生成知识图谱
催化中的结构化研究数据管理至关重要,尤其是对于大量数据,并且应遵循 FAIR 原则的指导,以便于数据的访问和兼容性。本体有助于以结构化和公平的方式组织知识。越来越多的科学出版物需要自动化方法来预选和获取所需的知识,同时最大限度地减少搜索相关出版物的工作量。虽然本体学习可用于创建结构化知识图,但命名实体识别允许对文本中的重要信息进行检测和分类。这项工作结合了本体学习和命名实体识别,用于从出版物中自动提取关键数据,并将隐式知识组织在机器和用户可读的知识图和数据中。 CatalysisIE 是用于催化研究的此类信息提取的预训练模型。本工作基于新的数据集使用并扩展了该模型,提高了模型针对数据集的精确度和召回率。在有关催化研究的两个数据集上对所提出的工作流程进行了验证。提供预先制定的 SPARQL 查询,以向研究人员展示所得知识图的可用性和适用性。
更新日期:2024-08-05
中文翻译:
通过催化研究相关文献的文本挖掘生成知识图谱
催化中的结构化研究数据管理至关重要,尤其是对于大量数据,并且应遵循 FAIR 原则的指导,以便于数据的访问和兼容性。本体有助于以结构化和公平的方式组织知识。越来越多的科学出版物需要自动化方法来预选和获取所需的知识,同时最大限度地减少搜索相关出版物的工作量。虽然本体学习可用于创建结构化知识图,但命名实体识别允许对文本中的重要信息进行检测和分类。这项工作结合了本体学习和命名实体识别,用于从出版物中自动提取关键数据,并将隐式知识组织在机器和用户可读的知识图和数据中。 CatalysisIE 是用于催化研究的此类信息提取的预训练模型。本工作基于新的数据集使用并扩展了该模型,提高了模型针对数据集的精确度和召回率。在有关催化研究的两个数据集上对所提出的工作流程进行了验证。提供预先制定的 SPARQL 查询,以向研究人员展示所得知识图的可用性和适用性。




































 京公网安备 11010802027423号
京公网安备 11010802027423号