Complex & Intelligent Systems ( IF 5.0 ) Pub Date : 2024-08-05 , DOI: 10.1007/s40747-024-01582-1 Wenyi Chen , Zongcheng Miao , Yang Qu , Guokai Shi
|
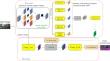
Semantic segmentation of urban street scenes has attracted much attention in the field of autonomous driving, which not only helps vehicles perceive the environment in real time, but also significantly improves the decision-making ability of autonomous driving systems. However, most of the current methods based on Convolutional Neural Network (CNN) mainly use coding the input image to a low resolution and then try to recover the high resolution, which leads to problems such as loss of spatial information, accumulation of errors, and difficulty in dealing with large-scale changes. To address these problems, in this paper, we propose a new semantic segmentation network (HRDLNet) for urban street scene images with high-resolution representation, which improves the accuracy of segmentation by always maintaining a high-resolution representation of the image. Specifically, we propose a feature extraction module (FHR) with high-resolution representation, which efficiently handles multi-scale targets and high-resolution image information by efficiently fusing high-resolution information and multi-scale features. Secondly, we design a multi-scale feature extraction enhancement (MFE) module, which significantly expands the sensory field of the network, thus enhancing the ability to capture correlations between image details and global contextual information. In addition, we introduce a dual-attention mechanism module (CSD), which dynamically adjusts the network to more accurately capture subtle features and rich semantic information in images. We trained and evaluated HRDLNet on the Cityscapes Dataset and the PASCAL VOC 2012 Augmented Dataset, and verified the model’s excellent performance in the field of urban streetscape image segmentation. The unique advantages of our proposed HRDLNet in the field of semantic segmentation of urban streetscapes are also verified by comparing it with the state-of-the-art methods.
中文翻译:
HRDLNet:具有城市街景图像高分辨率表示的语义分割网络
城市街道场景的语义分割在自动驾驶领域备受关注,不仅有助于车辆实时感知环境,还能显着提高自动驾驶系统的决策能力。然而,目前大多数基于卷积神经网络(CNN)的方法主要是将输入图像编码为低分辨率,然后尝试恢复高分辨率,这会导致空间信息丢失、误差累积等问题。难以应对大规模的变化。为了解决这些问题,在本文中,我们提出了一种新的用于具有高分辨率表示的城市街道场景图像的语义分割网络(HRDLNet),它通过始终保持图像的高分辨率表示来提高分割的准确性。具体来说,我们提出了一种具有高分辨率表示的特征提取模块(FHR),它通过有效融合高分辨率信息和多尺度特征来有效处理多尺度目标和高分辨率图像信息。其次,我们设计了多尺度特征提取增强(MFE)模块,显着扩展了网络的感知领域,从而增强了捕获图像细节和全局上下文信息之间的相关性的能力。此外,我们引入了双注意力机制模块(CSD),它动态调整网络以更准确地捕捉图像中的细微特征和丰富的语义信息。我们在Cityscapes数据集和PASCAL VOC 2012 Augmented Dataset上对HRDLNet进行了训练和评估,验证了模型在城市街景图像分割领域的优异性能。 通过与最先进的方法进行比较,我们提出的 HRDLNet 在城市街景语义分割领域的独特优势也得到了验证。










































 京公网安备 11010802027423号
京公网安备 11010802027423号