npj Digital Medicine ( IF 12.4 ) Pub Date : 2024-07-23 , DOI: 10.1038/s41746-024-01185-7 Qiao Jin 1 , Fangyuan Chen 2 , Yiliang Zhou 3 , Ziyang Xu 4 , Justin M Cheung 5 , Robert Chen 6 , Ronald M Summers 7 , Justin F Rousseau 8 , Peiyun Ni 9 , Marc J Landsman 10, 11 , Sally L Baxter 12 , Subhi J Al'Aref 13 , Yijia Li 14 , Alexander Chen 15 , Josef A Brejt 15 , Michael F Chiang 16 , Yifan Peng 3 , Zhiyong Lu 1
|
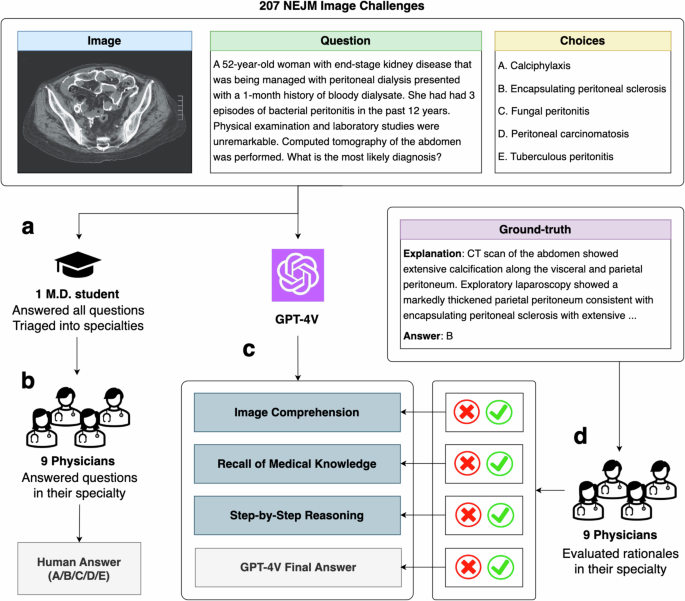
Recent studies indicate that Generative Pre-trained Transformer 4 with Vision (GPT-4V) outperforms human physicians in medical challenge tasks. However, these evaluations primarily focused on the accuracy of multi-choice questions alone. Our study extends the current scope by conducting a comprehensive analysis of GPT-4V’s rationales of image comprehension, recall of medical knowledge, and step-by-step multimodal reasoning when solving New England Journal of Medicine (NEJM) Image Challenges—an imaging quiz designed to test the knowledge and diagnostic capabilities of medical professionals. Evaluation results confirmed that GPT-4V performs comparatively to human physicians regarding multi-choice accuracy (81.6% vs. 77.8%). GPT-4V also performs well in cases where physicians incorrectly answer, with over 78% accuracy. However, we discovered that GPT-4V frequently presents flawed rationales in cases where it makes the correct final choices (35.5%), most prominent in image comprehension (27.2%). Regardless of GPT-4V’s high accuracy in multi-choice questions, our findings emphasize the necessity for further in-depth evaluations of its rationales before integrating such multimodal AI models into clinical workflows.
中文翻译:
医学领域多模态 GPT-4 视觉专家级准确性背后隐藏的缺陷
最近的研究表明,具有视觉功能的生成式预训练 Transformer 4 (GPT-4V) 在医疗挑战任务中的表现优于人类医生。然而,这些评估主要只关注多项选择题的准确性。我们的研究通过对 GPT-4V 在解决新英格兰医学杂志(NEJM) 图像挑战(一项设计的成像测验)时的图像理解、医学知识回忆和逐步多模态推理的基本原理进行全面分析,扩展了当前的范围。测试医疗专业人员的知识和诊断能力。评估结果证实,GPT-4V 在多项选择准确性方面的表现与人类医生相当(81.6% vs. 77.8%)。 GPT-4V 在医生回答错误的情况下也表现良好,准确率超过 78%。然而,我们发现 GPT-4V 在做出正确的最终选择 (35.5%) 的情况下经常呈现出有缺陷的基本原理,最突出的是图像理解 (27.2%)。尽管 GPT-4V 在多项选择题中具有很高的准确性,但我们的研究结果强调,在将此类多模态 AI 模型集成到临床工作流程之前,有必要对其基本原理进行进一步深入的评估。






























 京公网安备 11010802027423号
京公网安备 11010802027423号