Nature Machine Intelligence ( IF 18.8 ) Pub Date : 2024-07-23 , DOI: 10.1038/s42256-024-00872-0 Melissa Sanabria , Jonas Hirsch , Pierre M. Joubert , Anna R. Poetsch
|
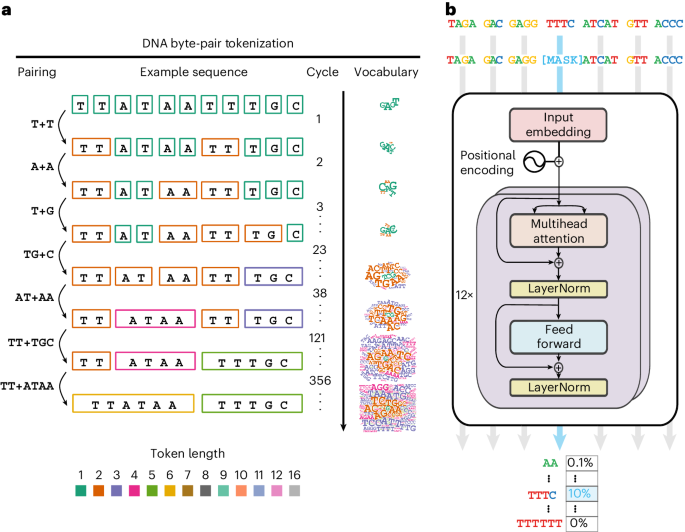
Deep-learning models that learn a sense of language on DNA have achieved a high level of performance on genome biological tasks. Genome sequences follow rules similar to natural language but are distinct in the absence of a concept of words. We established byte-pair encoding on the human genome and trained a foundation language model called GROVER (Genome Rules Obtained Via Extracted Representations) with the vocabulary selected via a custom task, next-k-mer prediction. The defined dictionary of tokens in the human genome carries best the information content for GROVER. Analysing learned representations, we observed that trained token embeddings primarily encode information related to frequency, sequence content and length. Some tokens are primarily localized in repeats, whereas the majority widely distribute over the genome. GROVER also learns context and lexical ambiguity. Average trained embeddings of genomic regions relate to functional genomics annotation and thus indicate learning of these structures purely from the contextual relationships of tokens. This highlights the extent of information content encoded by the sequence that can be grasped by GROVER. On fine-tuning tasks addressing genome biology with questions of genome element identification and protein–DNA binding, GROVER exceeds other models’ performance. GROVER learns sequence context, a sense for structure and language rules. Extracting this knowledge can be used to compose a grammar book for the code of life.
中文翻译:
DNA 语言模型 GROVER 学习人类基因组中的序列上下文
学习 DNA 语感的深度学习模型在基因组生物学任务上取得了高水平的性能。基因组序列遵循类似于自然语言的规则,但在缺乏单词概念的情况下是不同的。我们在人类基因组上建立了字节对编码,并训练了一个名为 GROVER(通过提取表示获得的基因组规则)的基础语言模型,其中词汇是通过自定义任务“next-k-mer 预测”选择的。人类基因组中定义的标记字典最能承载 GROVER 的信息内容。通过分析学习到的表示,我们观察到经过训练的令牌嵌入主要编码与频率、序列内容和长度相关的信息。一些标记主要集中在重复中,而大多数标记广泛分布在基因组中。 GROVER 还学习上下文和词汇歧义。基因组区域的平均训练嵌入与功能基因组注释相关,因此表明纯粹从标记的上下文关系中学习这些结构。这凸显了 GROVER 可以掌握的序列编码的信息内容的范围。在解决基因组生物学以及基因组元件识别和蛋白质-DNA 结合问题的微调任务中,GROVER 超越了其他模型的性能。 GROVER 学习序列上下文、结构感和语言规则。提取这些知识可以用来编写生命密码的语法书。

















































 京公网安备 11010802027423号
京公网安备 11010802027423号