当前位置:
X-MOL 学术
›
Biomass Bioenergy
›
论文详情
Our official English website, www.x-mol.net, welcomes your feedback! (Note: you will need to create a separate account there.)
Data analysis and machine learning aided integrated catalyst activity and process modelling for selective H2 production from biomass gasification
Biomass & Bioenergy ( IF 5.8 ) Pub Date : 2024-06-27 , DOI: 10.1016/j.biombioe.2024.107291 Swetha Karka , Reddi Kamesh
Biomass & Bioenergy ( IF 5.8 ) Pub Date : 2024-06-27 , DOI: 10.1016/j.biombioe.2024.107291 Swetha Karka , Reddi Kamesh
|
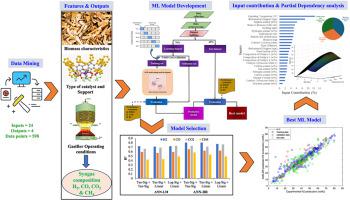
Hydrogen energy derived through biomass gasification is considered as one of the most sorted sustainable sources of renewable energy. This process enhances the H production from biomass in the presence of specific catalysts. Among different kinds of models that have been employed for this process, ML models adept at approximating non-linear functions and facilitate outcome prediction without detailed mathematical descriptions. Thus, the current work focuses on understanding structural-composition-operating-target property relationships, and integrated catalyst and process modelling using ML framework for thermo-catalytic biomass gasification to H production, and demonstrates outliers handling, data normalization for efficient handling of data-driven modelling with non-linear database. Linear, tree-based, kernel-based, and ANN models were developed with 589 datapoints screened from the 59 relevant papers with 24 inputs and 4 outputs (H, CO, CO, and CH as vol. %). Performance of these models are evaluated through 5-fold cross-validation and test data with the help of statistical measures. ANN with Basian-regularization learning algorithm using tan-sigmoid activation function in both layers, resulted superior performance in prediction of H production (RMSE = 6.85 & R = 0.80) and other output gases with high accuracy (i.e., minimum deviation from experimental data) compared to other ML models. Further, using the best ML model, input contribution and PDP analysis were performed to interpret the significance of predominate input parameters affecting on the product composition. Feature contribution analysis reveals that temperature, S/B ratio, catalyst support type, and sulphur content in biomass are significant parameters for enhancing H2 production from catalytic-biomass gasification, and PDP analysis discloses their optimal operating region.
中文翻译:

数据分析和机器学习辅助集成催化剂活性和过程建模,用于生物质气化选择性生产氢气
通过生物质气化产生的氢能被认为是最分类的可持续可再生能源之一。该过程在特定催化剂的存在下提高了生物质的氢气产量。在用于此过程的不同类型的模型中,机器学习模型擅长逼近非线性函数,并有助于结果预测,而无需详细的数学描述。因此,当前的工作重点是理解结构-组成-操作目标属性关系,以及使用机器学习框架对热催化生物质气化制氢进行集成催化剂和过程建模,并演示异常值处理、数据标准化以有效处理数据-使用非线性数据库驱动建模。线性、基于树、基于内核和 ANN 模型是通过从 59 篇相关论文中筛选出的 589 个数据点开发的,具有 24 个输入和 4 个输出(H、CO、CO 和 CH 作为体积%)。这些模型的性能通过 5 倍交叉验证和测试数据并借助统计措施进行评估。具有 Basian 正则化学习算法的 ANN 在两层中都使用 tan-sigmoid 激活函数,在预测 H 产量(RMSE = 6.85 & R = 0.80)和其他输出气体方面具有高精度(即与实验数据的最小偏差)的卓越性能与其他机器学习模型相比。此外,使用最佳的 ML 模型,进行输入贡献和 PDP 分析,以解释影响产品成分的主要输入参数的重要性。 特征贡献分析表明,温度、S/B比、催化剂载体类型和生物质中的硫含量是提高催化生物质气化制氢的重要参数,PDP分析揭示了它们的最佳操作区域。
更新日期:2024-06-27
中文翻译:
数据分析和机器学习辅助集成催化剂活性和过程建模,用于生物质气化选择性生产氢气
通过生物质气化产生的氢能被认为是最分类的可持续可再生能源之一。该过程在特定催化剂的存在下提高了生物质的氢气产量。在用于此过程的不同类型的模型中,机器学习模型擅长逼近非线性函数,并有助于结果预测,而无需详细的数学描述。因此,当前的工作重点是理解结构-组成-操作目标属性关系,以及使用机器学习框架对热催化生物质气化制氢进行集成催化剂和过程建模,并演示异常值处理、数据标准化以有效处理数据-使用非线性数据库驱动建模。线性、基于树、基于内核和 ANN 模型是通过从 59 篇相关论文中筛选出的 589 个数据点开发的,具有 24 个输入和 4 个输出(H、CO、CO 和 CH 作为体积%)。这些模型的性能通过 5 倍交叉验证和测试数据并借助统计措施进行评估。具有 Basian 正则化学习算法的 ANN 在两层中都使用 tan-sigmoid 激活函数,在预测 H 产量(RMSE = 6.85 & R = 0.80)和其他输出气体方面具有高精度(即与实验数据的最小偏差)的卓越性能与其他机器学习模型相比。此外,使用最佳的 ML 模型,进行输入贡献和 PDP 分析,以解释影响产品成分的主要输入参数的重要性。 特征贡献分析表明,温度、S/B比、催化剂载体类型和生物质中的硫含量是提高催化生物质气化制氢的重要参数,PDP分析揭示了它们的最佳操作区域。










































 京公网安备 11010802027423号
京公网安备 11010802027423号