Nature Medicine ( IF 58.7 ) Pub Date : 2024-06-28 , DOI: 10.1038/s41591-024-03113-4 Yuzhe Yang , Haoran Zhang , Judy W. Gichoya , Dina Katabi , Marzyeh Ghassemi
|
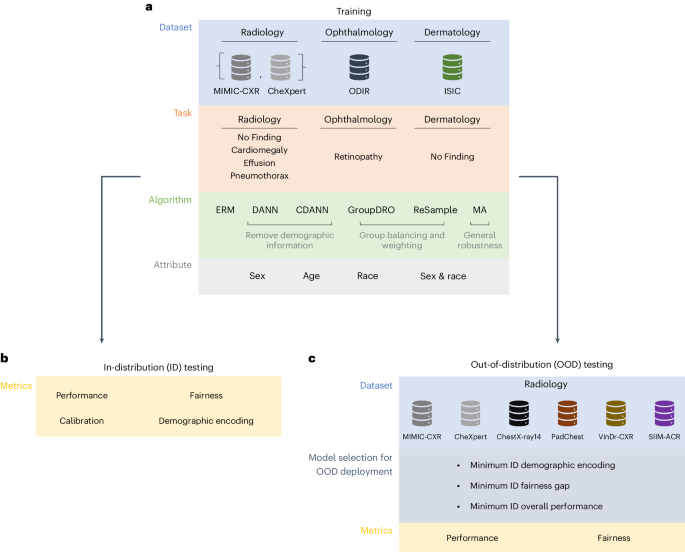
As artificial intelligence (AI) rapidly approaches human-level performance in medical imaging, it is crucial that it does not exacerbate or propagate healthcare disparities. Previous research established AI’s capacity to infer demographic data from chest X-rays, leading to a key concern: do models using demographic shortcuts have unfair predictions across subpopulations? In this study, we conducted a thorough investigation into the extent to which medical AI uses demographic encodings, focusing on potential fairness discrepancies within both in-distribution training sets and external test sets. Our analysis covers three key medical imaging disciplines—radiology, dermatology and ophthalmology—and incorporates data from six global chest X-ray datasets. We confirm that medical imaging AI leverages demographic shortcuts in disease classification. Although correcting shortcuts algorithmically effectively addresses fairness gaps to create ‘locally optimal’ models within the original data distribution, this optimality is not true in new test settings. Surprisingly, we found that models with less encoding of demographic attributes are often most ‘globally optimal’, exhibiting better fairness during model evaluation in new test environments. Our work establishes best practices for medical imaging models that maintain their performance and fairness in deployments beyond their initial training contexts, underscoring critical considerations for AI clinical deployments across populations and sites.
中文翻译:
公平医学成像人工智能在现实世界推广中的局限性
随着人工智能 (AI) 在医学成像方面的表现迅速接近人类水平,至关重要的是它不会加剧或扩大医疗保健差距。先前的研究证实人工智能有能力从胸部 X 光推断人口统计数据,这引发了一个关键问题:使用人口统计捷径的模型是否会对亚人群做出不公平的预测?在这项研究中,我们对医疗人工智能使用人口统计编码的程度进行了彻底调查,重点关注分布内训练集和外部测试集内潜在的公平性差异。我们的分析涵盖三个关键的医学影像学科——放射学、皮肤病学和眼科——并整合了来自六个全球胸部 X 射线数据集的数据。我们确认医学成像人工智能利用了疾病分类中的人口统计捷径。尽管通过算法纠正快捷方式可以有效地解决公平性差距,从而在原始数据分布中创建“局部最优”模型,但这种最优性在新的测试设置中并不真实。令人惊讶的是,我们发现人口统计属性编码较少的模型通常是最“全局最优”的,在新测试环境中的模型评估过程中表现出更好的公平性。我们的工作为医学成像模型建立了最佳实践,在超出初始训练环境的部署中保持其性能和公平性,强调了跨人群和站点的人工智能临床部署的关键考虑因素。










































 京公网安备 11010802027423号
京公网安备 11010802027423号