Nature Neuroscience ( IF 21.2 ) Pub Date : 2024-06-19 , DOI: 10.1038/s41593-024-01671-x Heiko H Schütt 1, 2 , Dongjae Kim 1, 3 , Wei Ji Ma 1
|
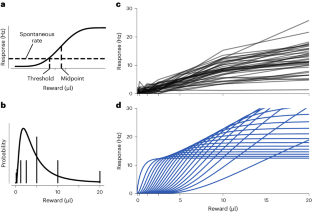
We use efficient coding principles borrowed from sensory neuroscience to derive the optimal neural population to encode a reward distribution. We show that the responses of dopaminergic reward prediction error neurons in mouse and macaque are similar to those of the efficient code in the following ways: the neurons have a broad distribution of midpoints covering the reward distribution; neurons with higher thresholds have higher gains, more convex tuning functions and lower slopes; and their slope is higher when the reward distribution is narrower. Furthermore, we derive learning rules that converge to the efficient code. The learning rule for the position of the neuron on the reward axis closely resembles distributional reinforcement learning. Thus, reward prediction error neuron responses may be optimized to broadcast an efficient reward signal, forming a connection between efficient coding and reinforcement learning, two of the most successful theories in computational neuroscience.
中文翻译:
奖励预测误差神经元实现有效的奖励代码
我们使用从感觉神经科学借用的有效编码原理来推导最佳神经群体来编码奖励分布。我们证明,小鼠和猕猴的多巴胺能奖励预测错误神经元的反应与有效代码的反应在以下方面相似:神经元具有覆盖奖励分布的广泛中点分布;阈值越高的神经元具有越高的增益、更多的凸调整函数和更低的斜率;当奖励分布较窄时,它们的斜率较高。此外,我们推导出收敛于高效代码的学习规则。奖励轴上神经元位置的学习规则与分布式强化学习非常相似。因此,奖励预测误差神经元响应可以被优化以广播有效的奖励信号,从而在高效编码和强化学习(计算神经科学中最成功的两种理论)之间形成联系。















































 京公网安备 11010802027423号
京公网安备 11010802027423号