Complex & Intelligent Systems ( IF 5.0 ) Pub Date : 2024-06-18 , DOI: 10.1007/s40747-024-01490-4 Xing Wang , Zixuan Wu , Biao Jin , Mingwei Lin , Fumin Zou , Lyuchao Liao
|
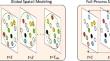
In the field of autonomous driving, trajectory prediction of traffic agents is an important and challenging problem. Fully capturing the complex spatio-temporal features in trajectory data is crucial for accurate trajectory prediction. This paper proposes a trajectory prediction model called multi-dimensional spatio-temporal feature fusion (MDSTF), which integrates multi-dimensional spatio-temporal features to model the trajectory information of traffic agents. In the spatial dimension, we employ graph convolutional networks (GCN) to capture the local spatial features of traffic agents, spatial attention mechanism to capture the global spatial features, and LSTM combined with spatial attention to capture the full-process spatial features of traffic agents. Subsequently, these three spatial features are fused using a gate fusion mechanism. Moreover, during the modeling of the full-process spatial features, LSTM is capable of capturing short-term temporal dependencies in the trajectory information of traffic agents. In the temporal dimension, we utilize a Transformer-based encoder to extract long-term temporal dependencies in the trajectory information of traffic agents, which are then fused with the short-term temporal dependencies captured by LSTM. Finally, we employ two temporal convolutional networks (TCN) to predict trajectories based on the fused spatio-temporal features. Experimental results on the ApolloScape trajectory dataset demonstrate that our proposed method outperforms state-of-the-art methods in terms of weighted sum of average displacement error (WSADE) and weighted sum of final displacement error (WSFDE) metrics. Compared to the best baseline model (S2TNet), our method achieves reductions of 4.37% and 6.23% respectively in these metrics.
中文翻译:
MDSTF:自动驾驶多维时空特征融合轨迹预测模型
在自动驾驶领域,交通主体的轨迹预测是一个重要且具有挑战性的问题。充分捕捉轨迹数据中复杂的时空特征对于准确的轨迹预测至关重要。本文提出了一种称为多维时空特征融合(MDSTF)的轨迹预测模型,该模型融合多维时空特征来对交通主体的轨迹信息进行建模。在空间维度上,我们采用图卷积网络(GCN)来捕获交通主体的局部空间特征,使用空间注意力机制来捕获全局空间特征,并使用LSTM结合空间注意力来捕获交通主体的全过程空间特征。随后,使用门融合机制融合这三个空间特征。此外,在对全过程空间特征进行建模时,LSTM能够捕获交通主体轨迹信息中的短期时间依赖性。在时间维度上,我们利用基于 Transformer 的编码器来提取交通代理轨迹信息中的长期时间依赖性,然后将其与 LSTM 捕获的短期时间依赖性融合。最后,我们采用两个时间卷积网络(TCN)来根据融合的时空特征来预测轨迹。 ApolloScape 轨迹数据集上的实验结果表明,我们提出的方法在平均位移误差加权和(WSADE)和最终位移误差加权和(WSFDE)指标方面优于最先进的方法。与最佳基线模型(S2TNet)相比,我们的方法在这些指标上分别降低了 4.37% 和 6.23%。










































 京公网安备 11010802027423号
京公网安备 11010802027423号