当前位置:
X-MOL 学术
›
Comput. Ind.
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
Causal knowledge extraction from long text maintenance documents
Computers in Industry ( IF 8.2 ) Pub Date : 2024-05-31 , DOI: 10.1016/j.compind.2024.104110 Brad Hershowitz , Melinda Hodkiewicz , Tyler Bikaun , Michael Stewart , Wei Liu
Computers in Industry ( IF 8.2 ) Pub Date : 2024-05-31 , DOI: 10.1016/j.compind.2024.104110 Brad Hershowitz , Melinda Hodkiewicz , Tyler Bikaun , Michael Stewart , Wei Liu
|
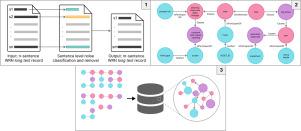
Large numbers of maintenance Work Request Notification (WRN) records are created by industry as part of standard business work flows. These digital records hold invaluable insights crucial to best practice in asset management. Of particular interest are the cause–effect relations in the WRN field. In this research we develop a two-stage deep learning pipeline to extract cause-and-effect triples and construct a causal graph database. A novel sentence-level noise removal method in the first stage filters out information extraneous to causal semantics. The second stage leverages a joint entity-and-relation extraction model to extract causal relations. To train the noise removal and causality extraction models we produced an annotated dataset of 1027 WRN records. The results for causality extraction as measured by F1-score are 83% and 92% for the identification of and entities respectively, and 78% for a correct causal relation between these entities. The pipeline is applied to a real-word, industrial plant dataset of 98,000 WRN records to produce a graph database. This work provides a framework for technical personnel to query the causes of equipment failures enabling answers to questions such as “what are the most , , and causes of failures at my facility?”.
中文翻译:

从长文本维护文档中提取因果知识
行业创建了大量维护工作请求通知 (WRN) 记录,作为标准业务工作流程的一部分。这些数字记录包含对资产管理最佳实践至关重要的宝贵见解。特别令人感兴趣的是 WRN 领域的因果关系。在这项研究中,我们开发了一个两阶段深度学习管道来提取因果三元组并构建因果图数据库。第一阶段中一种新颖的句子级噪声去除方法过滤掉与因果语义无关的信息。第二阶段利用联合实体和关系提取模型来提取因果关系。为了训练噪声消除和因果关系提取模型,我们生成了包含 1027 条 WRN 记录的带注释数据集。通过 F1 分数测量的因果关系提取结果,对于 和 实体的识别分别为 83% 和 92%,对于这些实体之间正确的因果关系,结果为 78%。该管道应用于包含 98,000 条 WRN 记录的真实工业工厂数据集,以生成图形数据库。这项工作为技术人员提供了一个查询设备故障原因的框架,可以回答诸如“我的设施中最常见的故障、故障的原因是什么?”等问题。
更新日期:2024-05-31
中文翻译:
从长文本维护文档中提取因果知识
行业创建了大量维护工作请求通知 (WRN) 记录,作为标准业务工作流程的一部分。这些数字记录包含对资产管理最佳实践至关重要的宝贵见解。特别令人感兴趣的是 WRN 领域的因果关系。在这项研究中,我们开发了一个两阶段深度学习管道来提取因果三元组并构建因果图数据库。第一阶段中一种新颖的句子级噪声去除方法过滤掉与因果语义无关的信息。第二阶段利用联合实体和关系提取模型来提取因果关系。为了训练噪声消除和因果关系提取模型,我们生成了包含 1027 条 WRN 记录的带注释数据集。通过 F1 分数测量的因果关系提取结果,对于 和 实体的识别分别为 83% 和 92%,对于这些实体之间正确的因果关系,结果为 78%。该管道应用于包含 98,000 条 WRN 记录的真实工业工厂数据集,以生成图形数据库。这项工作为技术人员提供了一个查询设备故障原因的框架,可以回答诸如“我的设施中最常见的故障、故障的原因是什么?”等问题。















































 京公网安备 11010802027423号
京公网安备 11010802027423号