Nature Communications ( IF 14.7 ) Pub Date : 2024-06-11 , DOI: 10.1038/s41467-024-49388-6 Juan-Ni Wu 1 , Tong Wang 1 , Yue Chen 1 , Li-Juan Tang 1 , Hai-Long Wu 1 , Ru-Qin Yu 1
|
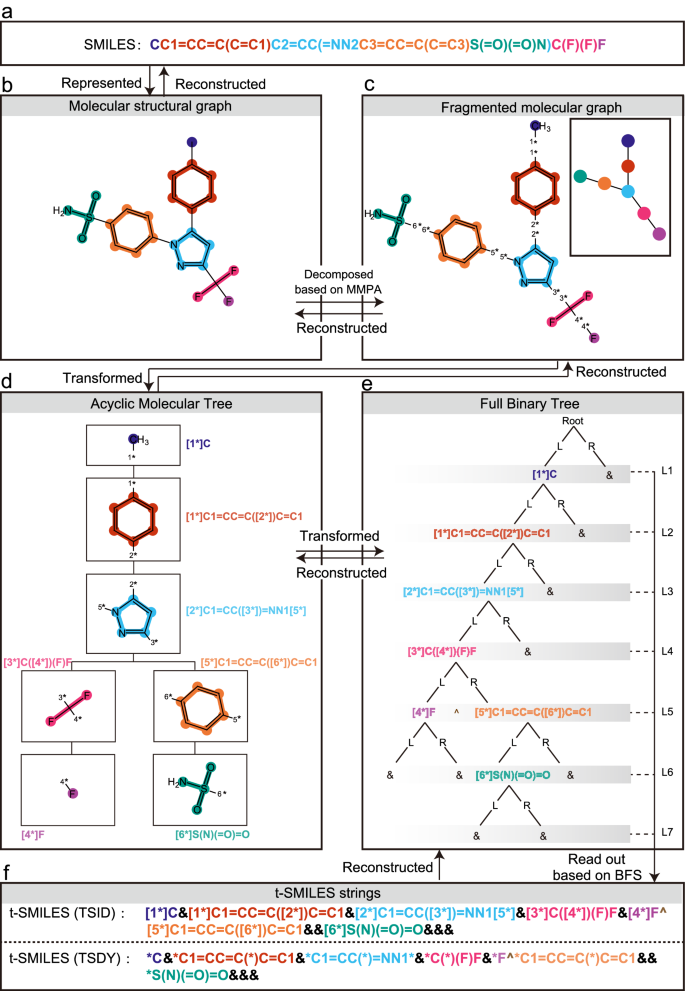
Effective representation of molecules is a crucial factor affecting the performance of artificial intelligence models. This study introduces a flexible, fragment-based, multiscale molecular representation framework called t-SMILES (tree-based SMILES) with three code algorithms: TSSA (t-SMILES with shared atom), TSDY (t-SMILES with dummy atom but without ID) and TSID (t-SMILES with ID and dummy atom). It describes molecules using SMILES-type strings obtained by performing a breadth-first search on a full binary tree formed from a fragmented molecular graph. Systematic evaluations using JTVAE, BRICS, MMPA, and Scaffold show the feasibility of constructing a multi-code molecular description system, where various descriptions complement each other, enhancing the overall performance. In addition, it can avoid overfitting and achieve higher novelty scores while maintaining reasonable similarity on labeled low-resource datasets, regardless of whether the model is original, data-augmented, or pre-trained then fine-tuned. Furthermore, it significantly outperforms classical SMILES, DeepSMILES, SELFIES and baseline models in goal-directed tasks. And it surpasses state-of-the-art fragment, graph and SMILES based approaches on ChEMBL, Zinc, and QM9.
中文翻译:
t-SMILES:用于从头配体设计的基于片段的分子表示框架
分子的有效表示是影响人工智能模型性能的关键因素。本研究引入了一种灵活的、基于片段的多尺度分子表示框架,称为 t-SMILES(基于树的 SMILES),具有三种代码算法:TSSA(具有共享原子的 t-SMILES)、TSDY(具有虚拟原子但没有 ID 的 t-SMILES) )和 TSID(带有 ID 和虚拟原子的 t-SMILES)。它使用 SMILES 类型的字符串来描述分子,该字符串是通过对由碎片分子图形成的完整二叉树执行广度优先搜索而获得的。使用 JTVAE、BRICS、MMPA 和 Scaffold 进行的系统评估表明了构建多代码分子描述系统的可行性,其中各种描述相互补充,提高了整体性能。此外,它可以避免过度拟合并获得更高的新颖性分数,同时在标记的低资源数据集上保持合理的相似性,无论模型是原始的、数据增强的还是预先训练然后微调的。此外,它在目标导向任务中显着优于经典的 SMILES、DeepSMILES、SELFIES 和基线模型。它超越了基于 ChEMBL、Zinc 和 QM9 的最先进的片段、图形和 SMILES 方法。





























 京公网安备 11010802027423号
京公网安备 11010802027423号