International Journal of Computer Vision ( IF 11.6 ) Pub Date : 2024-06-02 , DOI: 10.1007/s11263-024-02130-7 Ziwei Wang , Han Xiao , Jie Zhou , Jiwen Lu
|
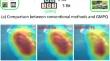
In this paper, we propose a generalizable mixed-precision quantization (GMPQ) method for efficient inference. Conventional methods require the consistency of datasets for bitwidth search and model deployment to guarantee the policy optimality, leading to heavy search cost on challenging large-scale datasets in realistic applications. On the contrary, our GMPQ searches the mixed-quantization policy that can be generalized to large-scale datasets with only a small amount of data, so that the search cost is significantly reduced without performance degradation. Specifically, we observe that locating network attribution correctly is general ability for accurate visual analysis across different data distribution. Therefore, despite of pursuing higher accuracy and lower model complexity, we preserve attribution rank consistency between the quantized models and their full-precision counterparts via capacity-aware attribution imitation for generalizable mixed-precision quantization strategy search, where the capacity of quantized networks is considered to fully utilize the network capacity without insufficiency. Since slight noise in attribution is amplified by discrete ranking operations with significant rank errors, mimicking the attribution ranks of the full-precision models obstructs the quantized networks to correctly locate the attribution. To address this, we further present a robust generalizable mixed-precision quantization method to smooth the attribution for rank error alleviation by hierarchical attribution partitioning, which efficiently partitions the attribution pixels in high spatial resolution and assigns the same attribution value for pixels within a group. Moreover, we propose dynamic capacity-aware attribution imitation to adjust the concentration degree of the attribution according to sample hardness, so that sufficient model capacity is achieved with full utilization for each image. Extensive experiments on image classification and object detection show that our GMPQ and R-GMPQ obtain competitive accuracy-complexity trade-offs with significantly reduced search cost compared to the state-of-the-art mixed-precision networks.
中文翻译:
通过归因模仿学习可推广的混合精度量化
在本文中,我们提出了一种用于高效推理的通用混合精度量化(GMPQ)方法。传统方法需要位宽搜索和模型部署数据集的一致性来保证策略最优性,导致在实际应用中挑战大规模数据集时搜索成本高昂。相反,我们的GMPQ搜索混合量化策略,可以推广到仅需要少量数据的大规模数据集,从而在不降低性能的情况下显着降低搜索成本。具体来说,我们观察到正确定位网络归因是跨不同数据分布进行准确视觉分析的一般能力。因此,尽管追求更高的准确性和更低的模型复杂性,我们通过容量感知的归因模仿来保持量化模型与其全精度模型之间的归因等级一致性,以进行可推广的混合精度量化策略搜索,其中考虑了量化网络的容量充分利用网络容量而不出现不足。由于具有显着排名误差的离散排名操作会放大归因中的轻微噪声,因此模仿全精度模型的归因排名会阻碍量化网络正确定位归因。为了解决这个问题,我们进一步提出了一种鲁棒的可泛化混合精度量化方法,通过分层归因划分来平滑归因以减轻排名误差,该方法以高空间分辨率有效地划分归因像素,并为组内的像素分配相同的归因值。 此外,我们提出动态容量感知归因模拟,根据样本硬度调整归因的集中程度,从而在充分利用每张图像的情况下实现足够的模型容量。关于图像分类和目标检测的大量实验表明,与最先进的混合精度网络相比,我们的 GMPQ 和 R-GMPQ 获得了有竞争力的精度-复杂性权衡,并且显着降低了搜索成本。
































 京公网安备 11010802027423号
京公网安备 11010802027423号