Diabetologia ( IF 8.4 ) Pub Date : 2024-05-27 , DOI: 10.1007/s00125-024-06184-7 Benedetta Salvatori 1 , Silke Wegener 2 , Grammata Kotzaeridi 3 , Annika Herding 3 , Florian Eppel 3 , Iris Dressler-Steinbach 2 , Wolfgang Henrich 2 , Agnese Piersanti 4 , Micaela Morettini 4 , Andrea Tura 1 , Christian S Göbl 3, 5
|
Aims/hypothesis
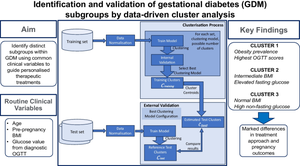
Gestational diabetes mellitus (GDM) is a heterogeneous condition. Given such variability among patients, the ability to recognise distinct GDM subgroups using routine clinical variables may guide more personalised treatments. Our main aim was to identify distinct GDM subtypes through cluster analysis using routine clinical variables, and analyse treatment needs and pregnancy outcomes across these subgroups.
Methods
In this cohort study, we analysed datasets from a total of 2682 women with GDM treated at two central European hospitals (1865 participants from Charité University Hospital in Berlin and 817 participants from the Medical University of Vienna), collected between 2015 and 2022. We evaluated various clustering models, including k-means, k-medoids and agglomerative hierarchical clustering. Internal validation techniques were used to guide best model selection, while external validation on independent test sets was used to assess model generalisability. Clinical outcomes such as specific treatment needs and maternal and fetal complications were analysed across the identified clusters.
Results
Our optimal model identified three clusters from routinely available variables, i.e. maternal age, pre-pregnancy BMI (BMIPG) and glucose levels at fasting and 60 and 120 min after the diagnostic OGTT (OGTT0, OGTT60 and OGTT120, respectively). Cluster 1 was characterised by the highest OGTT values and obesity prevalence. Cluster 2 displayed intermediate BMIPG and elevated OGTT0, while cluster 3 consisted mainly of participants with normal BMIPG and high values for OGTT60 and OGTT120. Treatment modalities and clinical outcomes varied among clusters. In particular, cluster 1 participants showed a much higher need for glucose-lowering medications (39.6% of participants, compared with 12.9% and 10.0% in clusters 2 and 3, respectively, p<0.0001). Cluster 1 participants were also at higher risk of delivering large-for-gestational-age infants. Differences in the type of insulin-based treatment between cluster 2 and cluster 3 were observed in the external validation cohort.
Conclusions/interpretation
Our findings confirm the heterogeneity of GDM. The identification of subgroups (clusters) has the potential to help clinicians define more tailored treatment approaches for improved maternal and neonatal outcomes.
Graphical Abstract
中文翻译:
通过数据驱动的聚类分析识别和验证妊娠糖尿病亚组
目标/假设
妊娠期糖尿病(GDM)是一种异质性疾病。鉴于患者之间存在这种差异,使用常规临床变量识别不同 GDM 亚组的能力可能会指导更个性化的治疗。我们的主要目的是通过使用常规临床变量的聚类分析来识别不同的 GDM 亚型,并分析这些亚组的治疗需求和妊娠结局。
方法
在这项队列研究中,我们分析了 2015 年至 2022 年间在两家中欧医院接受治疗的总共 2682 名 GDM 女性的数据集(1865 名参与者来自柏林夏里特大学医院,817 名参与者来自维也纳医科大学)。我们评估了各种聚类模型,包括k均值、 k中心点和凝聚层次聚类。内部验证技术用于指导最佳模型选择,而独立测试集的外部验证用于评估模型的通用性。对确定的集群中的具体治疗需求以及母婴并发症等临床结果进行了分析。
结果
我们的最佳模型从常规可用变量中识别出三个簇,即母亲年龄、孕前 BMI (BMIPG) 以及空腹以及诊断性 OGTT 后 60 分钟和 120 分钟的血糖水平(分别为 OGTT0、OGTT60 和 OGTT120)。聚类 1 的特点是 OGTT 值和肥胖患病率最高。集群 2 显示中等 BMIPG 和升高的 OGTT0,而集群 3 主要由 BMIPG 正常但 OGTT60 和 OGTT120 值较高的参与者组成。不同集群的治疗方式和临床结果各不相同。特别是,组 1 参与者对降糖药物的需求要高得多(39.6% 的参与者,而组 2 和组 3 中的参与者分别为 12.9% 和 10.0%, p <0.0001)。第 1 组参与者生下大于胎龄儿的风险也较高。在外部验证队列中观察到组 2 和组 3 之间基于胰岛素的治疗类型存在差异。
结论/解释
我们的研究结果证实了 GDM 的异质性。亚组(簇)的识别有可能帮助临床医生确定更有针对性的治疗方法,以改善孕产妇和新生儿的结局。















































 京公网安备 11010802027423号
京公网安备 11010802027423号