Nature Biomedical Engineering ( IF 26.8 ) Pub Date : 2024-05-20 , DOI: 10.1038/s41551-024-01207-5 Alexander B Silva 1, 2, 3 , Jessie R Liu 1, 2, 3 , Sean L Metzger 1, 2, 3 , Ilina Bhaya-Grossman 1, 2, 3 , Maximilian E Dougherty 1 , Margaret P Seaton 1 , Kaylo T Littlejohn 1, 2, 4 , Adelyn Tu-Chan 5 , Karunesh Ganguly 2, 5 , David A Moses 1, 2 , Edward F Chang 1, 2, 3
|
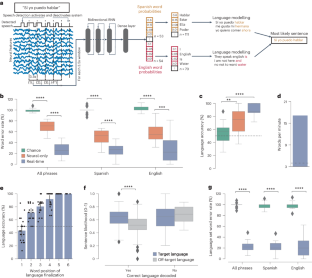
Advancements in decoding speech from brain activity have focused on decoding a single language. Hence, the extent to which bilingual speech production relies on unique or shared cortical activity across languages has remained unclear. Here, we leveraged electrocorticography, along with deep-learning and statistical natural-language models of English and Spanish, to record and decode activity from speech-motor cortex of a Spanish–English bilingual with vocal-tract and limb paralysis into sentences in either language. This was achieved without requiring the participant to manually specify the target language. Decoding models relied on shared vocal-tract articulatory representations across languages, which allowed us to build a syllable classifier that generalized across a shared set of English and Spanish syllables. Transfer learning expedited training of the bilingual decoder by enabling neural data recorded in one language to improve decoding in the other language. Overall, our findings suggest shared cortical articulatory representations that persist after paralysis and enable the decoding of multiple languages without the need to train separate language-specific decoders.
中文翻译:
由语言之间共享的皮质发音表征驱动的双语语音神经假体
从大脑活动解码语音的进步主要集中在解码单一语言上。因此,双语语音产生在多大程度上依赖于跨语言独特或共享的皮层活动仍不清楚。在这里,我们利用皮层电图以及英语和西班牙语的深度学习和统计自然语言模型,将声带和肢体麻痹的西班牙语-英语双语者的言语运动皮层的活动记录并解码为任何一种语言的句子。这是在不需要参与者手动指定目标语言的情况下实现的。解码模型依赖于跨语言共享的声带发音表示,这使我们能够构建一个音节分类器,该分类器可以泛化到一组共享的英语和西班牙语音节中。迁移学习通过启用以一种语言记录的神经数据来改进另一种语言的解码,从而加快了双语解码器的训练。总体而言,我们的研究结果表明,共享的皮层发音表示在瘫痪后仍然存在,并且无需训练单独的语言特定解码器即可解码多种语言。






























 京公网安备 11010802027423号
京公网安备 11010802027423号