当前位置:
X-MOL 学术
›
WIREs Data Mining Knowl. Discov.
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
A review of reasoning characteristics of RDF‐based Semantic Web systems
WIREs Data Mining and Knowledge Discovery ( IF 6.4 ) Pub Date : 2024-03-28 , DOI: 10.1002/widm.1537 Simona Colucci 1 , Francesco M. Donini 2 , Eugenio Di Sciascio 1
WIREs Data Mining and Knowledge Discovery ( IF 6.4 ) Pub Date : 2024-03-28 , DOI: 10.1002/widm.1537 Simona Colucci 1 , Francesco M. Donini 2 , Eugenio Di Sciascio 1
Affiliation
|
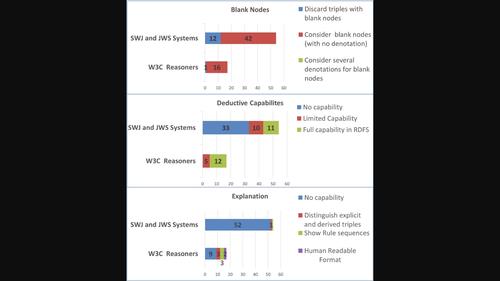
Presented as a research challenge in 2001, the Semantic Web (SW) is now a mature technology, used in several cross‐domain applications. One of its key benefits is a formal semantics of its RDF data format, which enables a system to validate data, infer implicit knowledge by automated reasoning, and explain it to a user; yet the analysis presented here of 71 RDF‐based SW systems (out of which 17 reasoners) reveals that the exploitation of such semantics varies a lot among all SW applications. Since the simple enumeration of systems, each one with its characteristics, might result in a clueless listing, we borrow from Software Engineering the idea of maturity model, and organize our classification around it. Our model has three orthogonal dimensions: treatment of blank nodes, degree of deductive capabilities, and explanation of results. For each dimension, we define 3–4 levels of increasing exploitation of semantics, corresponding to an increasingly sophisticated output in that dimension. Each system is then classified in each dimension, based on its documentation and published articles. The distribution of systems along each dimension is depicted in the graphical abstract. We deliberately exclude resources consumption (time and space) since it is a dimension not peculiar to SW.This article is categorized under: Fundamental Concepts of Data and Knowledge > Knowledge Representation Fundamental Concepts of Data and Knowledge > Explainable AI
中文翻译:

基于RDF的语义Web系统推理特性综述
语义网 (SW) 在 2001 年作为一项研究挑战提出,现在已成为一项成熟的技术,用于多个跨域应用程序。它的主要优点之一是其 RDF 数据格式的形式语义,使系统能够验证数据、通过自动推理推断隐式知识并向用户解释;然而,这里对 71 个基于 RDF 的软件系统(其中 17 个推理器)的分析表明,在所有软件应用程序中,此类语义的利用差异很大。由于简单地列举系统(每个系统都有其特征)可能会导致毫无头绪的列表,因此我们借用软件工程的成熟度模型的思想,并围绕它组织我们的分类。我们的模型具有三个正交维度:空白节点的处理、演绎能力的程度以及结果的解释。对于每个维度,我们定义了 3-4 个不断增加的语义利用级别,对应于该维度中日益复杂的输出。然后,根据每个系统的文档和已发表的文章,对每个系统进行各个维度的分类。图形摘要中描述了系统沿每个维度的分布。我们故意排除资源消耗(时间和空间),因为它不是 SW 所特有的一个维度。本文分类如下: 数据和知识的基本概念 > 知识表示 数据和知识的基本概念 > 可解释的人工智能
更新日期:2024-03-28
中文翻译:
基于RDF的语义Web系统推理特性综述
语义网 (SW) 在 2001 年作为一项研究挑战提出,现在已成为一项成熟的技术,用于多个跨域应用程序。它的主要优点之一是其 RDF 数据格式的形式语义,使系统能够验证数据、通过自动推理推断隐式知识并向用户解释;然而,这里对 71 个基于 RDF 的软件系统(其中 17 个推理器)的分析表明,在所有软件应用程序中,此类语义的利用差异很大。由于简单地列举系统(每个系统都有其特征)可能会导致毫无头绪的列表,因此我们借用软件工程的成熟度模型的思想,并围绕它组织我们的分类。我们的模型具有三个正交维度:空白节点的处理、演绎能力的程度以及结果的解释。对于每个维度,我们定义了 3-4 个不断增加的语义利用级别,对应于该维度中日益复杂的输出。然后,根据每个系统的文档和已发表的文章,对每个系统进行各个维度的分类。图形摘要中描述了系统沿每个维度的分布。我们故意排除资源消耗(时间和空间),因为它不是 SW 所特有的一个维度。本文分类如下:





























 京公网安备 11010802027423号
京公网安备 11010802027423号