Nature Machine Intelligence ( IF 18.8 ) Pub Date : 2024-03-07 , DOI: 10.1038/s42256-024-00802-0 A. Emin Orhan , Brenden M. Lake
|
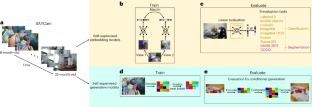
Young children develop sophisticated internal models of the world based on their visual experience. Can such models be learned from a child’s visual experience without strong inductive biases? To investigate this, we train state-of-the-art neural networks on a realistic proxy of a child’s visual experience without any explicit supervision or domain-specific inductive biases. Specifically, we train both embedding models and generative models on 200 hours of headcam video from a single child collected over two years and comprehensively evaluate their performance in downstream tasks using various reference models as yardsticks. On average, the best embedding models perform at a respectable 70% of a high-performance ImageNet-trained model, despite substantial differences in training data. They also learn broad semantic categories and object localization capabilities without explicit supervision, but they are less object-centric than models trained on all of ImageNet. Generative models trained with the same data successfully extrapolate simple properties of partially masked objects, like their rough outline, texture, colour or orientation, but struggle with finer object details. We replicate our experiments with two other children and find remarkably consistent results. Broadly useful high-level visual representations are thus robustly learnable from a sample of a child’s visual experience without strong inductive biases.
中文翻译:
从儿童的角度学习高级视觉表征,而没有强烈的归纳偏差
幼儿根据他们的视觉体验发展出复杂的内部世界模型。这样的模型可以从孩子的视觉体验中学习而没有强烈的归纳偏差吗?为了研究这一点,我们在儿童视觉体验的真实代理上训练最先进的神经网络,没有任何明确的监督或特定领域的归纳偏差。具体来说,我们在两年内收集的单个孩子的 200 小时头部摄像头视频上训练嵌入模型和生成模型,并使用各种参考模型作为标准,综合评估它们在下游任务中的表现。平均而言,尽管训练数据存在显着差异,但最佳嵌入模型的性能仅为高性能 ImageNet 训练模型的 70%。它们还可以在没有明确监督的情况下学习广泛的语义类别和对象定位能力,但它们比在所有 ImageNet 上训练的模型更少以对象为中心。使用相同数据训练的生成模型成功地推断出部分遮罩对象的简单属性,例如它们的粗糙轮廓、纹理、颜色或方向,但难以处理更精细的对象细节。我们对另外两个孩子重复了我们的实验,并发现了非常一致的结果。因此,可以从儿童的视觉体验样本中可靠地学习广泛有用的高级视觉表示,而无需强烈的归纳偏差。





































 京公网安备 11010802027423号
京公网安备 11010802027423号