当前位置:
X-MOL 学术
›
WIREs Data Mining Knowl. Discov.
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
Comparing programming languages for data analytics: Accuracy of estimation in Python and R
WIREs Data Mining and Knowledge Discovery ( IF 6.4 ) Pub Date : 2024-02-02 , DOI: 10.1002/widm.1531 Chelsey Hill 1 , Lanqing Du 2 , Marina Johnson 1 , B. D. McCullough 2
WIREs Data Mining and Knowledge Discovery ( IF 6.4 ) Pub Date : 2024-02-02 , DOI: 10.1002/widm.1531 Chelsey Hill 1 , Lanqing Du 2 , Marina Johnson 1 , B. D. McCullough 2
Affiliation
|
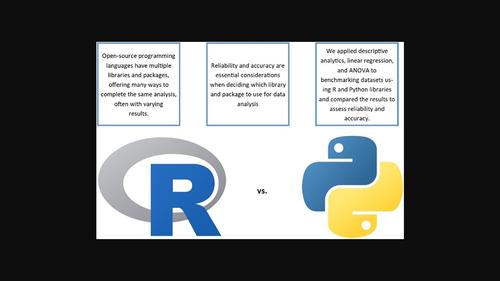
Several open-source programming languages, particularly R and Python, are utilized in industry and academia for statistical data analysis, data mining, and machine learning. While most commercial software programs and programming languages provide a single way to deliver a statistical procedure, open-source programming languages have multiple libraries and packages offering many ways to complete the same analysis, often with varying results. Applying the same statistical method across these different libraries and packages can lead to entirely different solutions due to the differences in their implementations. Therefore, reliability and accuracy should be essential considerations when making library and package usage decisions while conducting statistical analysis using open source programming languages. Instead, most users take this for granted, assuming that their chosen libraries and packages produce accurate results for their statistical analysis. To this extent, this study assesses the estimation accuracy and reliability of Python and R's various libraries and packages by evaluating the univariate summary statistics, analysis of variance (ANOVA), and linear regression procedures using benchmarking data from the National Institutes of Standards and Technology (NIST). Further, experimental results are presented comparing machine learning methods for classification and regression. The libraries and packages assessed in this study include the stats package in R and Pandas, Statistics, NumPy, statsmodels, SciPy, statsmodels, scikit-learn, and pingouin in Python. The results show that the stats package in R and statsmodels library in Python are reliable for univariate summary statistics. In contrast, Python's scikit-learn library produces the most accurate results and is recommended for ANOVA. Among the libraries and packages assessed for linear regression, the results demonstrated that the stats package in R is more reliable, accurate, and flexible; thus, it is recommended for linear regression analysis. Further, we present results and recommendations for machine learning using R and Python.
中文翻译:

比较数据分析编程语言:Python 和 R 中估计的准确性
工业界和学术界使用多种开源编程语言(尤其是 R 和 Python)进行统计数据分析、数据挖掘和机器学习。虽然大多数商业软件程序和编程语言提供单一方法来提供统计过程,但开源编程语言具有多个库和包,提供多种方法来完成相同的分析,但通常会产生不同的结果。由于实现的差异,在这些不同的库和包中应用相同的统计方法可能会导致完全不同的解决方案。因此,在使用开源编程语言进行统计分析时,在做出库和包使用决策时,可靠性和准确性应该是重要的考虑因素。相反,大多数用户认为这是理所当然的,假设他们选择的库和包可以为他们的统计分析产生准确的结果。就此而言,本研究通过使用美国国家标准与技术研究院的基准数据评估单变量汇总统计、方差分析 (ANOVA) 和线性回归程序,评估了 Python 和 R 的各种库和包的估计准确性和可靠性。美国国家标准技术研究所)。此外,还提供了比较机器学习方法的分类和回归的实验结果。本研究评估的库和包包括 R 和 Pandas 中的 stats 包、Statistics、NumPy、statsmodels、SciPy、statsmodels、scikit-learn 和 Python 中的 pingouin。结果表明,R 中的 stats 包和 Python 中的 statsmodels 库对于单变量汇总统计是可靠的。相比之下,Python 的 scikit-learn 库可生成最准确的结果,建议用于方差分析。在评估线性回归的库和包中,结果表明 R 中的 stats 包更加可靠、准确和灵活;因此,建议进行线性回归分析。此外,我们还提出了使用 R 和 Python 进行机器学习的结果和建议。
更新日期:2024-02-06
中文翻译:
比较数据分析编程语言:Python 和 R 中估计的准确性
工业界和学术界使用多种开源编程语言(尤其是 R 和 Python)进行统计数据分析、数据挖掘和机器学习。虽然大多数商业软件程序和编程语言提供单一方法来提供统计过程,但开源编程语言具有多个库和包,提供多种方法来完成相同的分析,但通常会产生不同的结果。由于实现的差异,在这些不同的库和包中应用相同的统计方法可能会导致完全不同的解决方案。因此,在使用开源编程语言进行统计分析时,在做出库和包使用决策时,可靠性和准确性应该是重要的考虑因素。相反,大多数用户认为这是理所当然的,假设他们选择的库和包可以为他们的统计分析产生准确的结果。就此而言,本研究通过使用美国国家标准与技术研究院的基准数据评估单变量汇总统计、方差分析 (ANOVA) 和线性回归程序,评估了 Python 和 R 的各种库和包的估计准确性和可靠性。美国国家标准技术研究所)。此外,还提供了比较机器学习方法的分类和回归的实验结果。本研究评估的库和包包括 R 和 Pandas 中的 stats 包、Statistics、NumPy、statsmodels、SciPy、statsmodels、scikit-learn 和 Python 中的 pingouin。结果表明,R 中的 stats 包和 Python 中的 statsmodels 库对于单变量汇总统计是可靠的。相比之下,Python 的 scikit-learn 库可生成最准确的结果,建议用于方差分析。在评估线性回归的库和包中,结果表明 R 中的 stats 包更加可靠、准确和灵活;因此,建议进行线性回归分析。此外,我们还提出了使用 R 和 Python 进行机器学习的结果和建议。

















































 京公网安备 11010802027423号
京公网安备 11010802027423号