Scientific Reports ( IF 3.8 ) Pub Date : 2023-12-16 , DOI: 10.1038/s41598-023-49708-8 Ayako Yagahara 1 , Noriya Yokohama 2
|
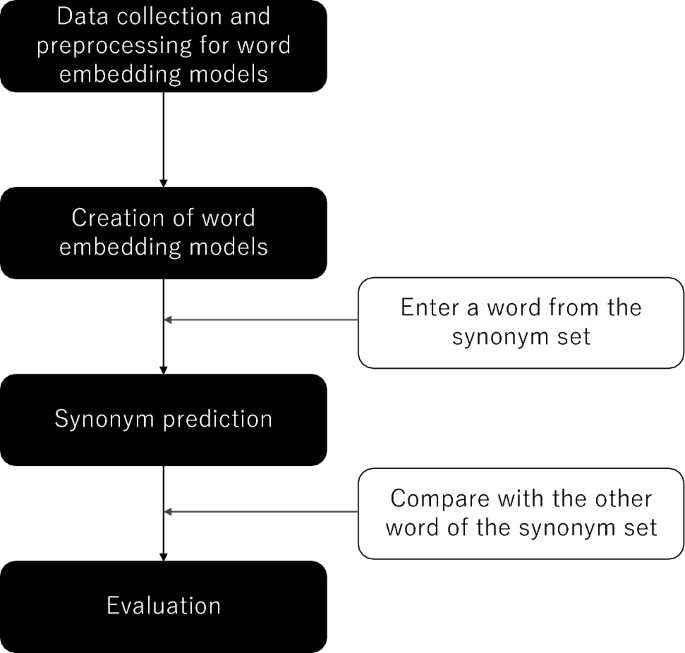
The terminology in radiological technology is crucial, encompassing a broad range of principles from radiation to medical imaging, and involving various specialists. This study aimed to evaluate the accuracy of automatic synonym detection considering the characteristics of the Japanese language by Word2vec and fastText in the radiological technology field for the terminology elaboration. We collected around 340 thousand abstracts in Japanese. First, preprocessing of the abstract data was performed. Then, training models were created with Word2vec and fastText with different architectures: continuous bag-of-words (CBOW) and skip-gram, and vector sizes. Baseline synonym sets were curated by two experts, utilizing terminology resources specific to radiological technology. A term in the dataset input into the generated models, and the top-10 synonym candidates which had high cosine similarities were obtained. Subsequently, precision, recall, F1-score, and accuracy for each model were calculated. The fastText model with CBOW at 300 dimensions was most precise in synonym detection, excelling in cases with shared n-grams. Conversely, fastText with skip-gram and Word2vec were favored for synonyms without common n-grams. In radiological technology, where n-grams are prevalent, fastText with CBOW proved advantageous, while in informatics, characterized by abbreviations and transliterations, Word2vec with CBOW was more effective.
中文翻译:
放射技术领域使用词嵌入的日语同义词识别准确率比较
放射技术中的术语至关重要,涵盖从辐射到医学成像的广泛原理,并涉及各种专家。本研究旨在评估放射技术领域中考虑日语特点的 Word2vec 和 fastText 自动同义词检测的准确性,以进行术语阐述。我们收集了大约 34 万条日语摘要。首先,对抽象数据进行预处理。然后,使用 Word2vec 和 fastText 创建具有不同架构的训练模型:连续词袋 (CBOW) 和 Skip-gram 以及向量大小。基线同义词集由两位专家利用放射技术特有的术语资源策划。将数据集中的术语输入到生成的模型中,并获得具有高余弦相似度的前 10 个同义词候选者。随后,计算每个模型的精确度、召回率、F1 分数和准确度。具有 300 维 CBOW 的 fastText 模型在同义词检测方面最为精确,在共享 n 元语法的情况下表现出色。相反,带有skip-gram 和Word2vec 的fastText 更适合没有常见n-gram 的同义词。在 n-gram 盛行的放射技术中,fastText 结合 CBOW 被证明是有利的,而在以缩写和音译为特征的信息学中,Word2vec 结合 CBOW 更有效。

















































 京公网安备 11010802027423号
京公网安备 11010802027423号