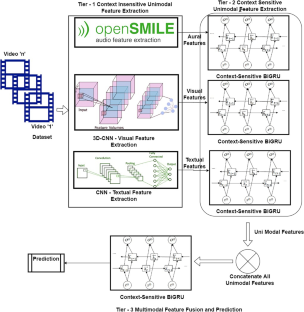
人工智能 (AI) 中最具吸引力的多学科研究领域之一是情感分析 (SA)。由于多种模态之间错综复杂且互补的相互作用,多模态情感分析(MSA)是一项极其困难但应用范围广泛的工作。在多模态情感分析领域,人们提出了许多深度学习模型和不同的技术,但它们没有研究单词的显式上下文,也无法对句子的不同组成部分进行建模。因此,这种多样化数据的全部潜力尚未得到充分开发。在本研究中,提出了一种上下文敏感的多层深度学习框架(CS-MDF),用于多模态数据的情感分析。CS-MDF 使用三层架构来提取上下文相关信息。第一层利用卷积神经网络 (CNN) 提取基于文本的特征,利用 3D-CNN 模型提取视觉特征,并利用大特征空间提取的开源媒体解释 (openSMILE) 工具包提取音频特征。专注于从话语中提取单峰特征。这种级别的提取在确定特征时会忽略上下文相关的数据。CNN 适用于文本数据,因为它们对于识别数据中的本地模式和依赖性特别有用。第二层使用从第一层提取的特征。上下文相关的数据在这一层中,使用双向门控循环单元 (BiGRU) 提取单峰特征,该单元用于理解话语间链接并发现上下文证据。第二层的输出被组合并传递到第三层,第三层融合了来自不同模态的特征,并训练提供最终分类的单个 BiGRU 模型。该方法将 BiGRU 模型应用于顺序数据处理,利用两种模态的优点并捕获它们的相互依赖性。在六个现实数据集上获得的实验结果(Flickr Images数据集、多视图情感分析数据集、Getty Images 数据集、Balanced Twitter for Sentiment Analysis 数据集、CMU-MOSI 数据集)表明,与十种最先进的方法相比,所提出的 CS-MDF 模型取得了更好的性能,其中通过 F1 分数、精度、准确性和召回指标进行验证。对所提出的框架进行了消融研究,证明了设计的可行性。GradCAM 可视化技术用于可视化由所提出的 CS-MDF 模型学习的对齐输入图像-文本对。
 "点击查看英文标题和摘要"
"点击查看英文标题和摘要"
A context-sensitive multi-tier deep learning framework for multimodal sentiment analysis
One of the most appealing multidisciplinary research areas in Artificial Intelligence (AI) is Sentiment Analysis (SA). Due to the intricate and complementary interactions between several modalities, Multimodal Sentiment Analysis (MSA) is an extremely difficult work that has a wide range of applications. In the subject of multimodal sentiment analysis, numerous deep learning models and different techniques have been suggested, but they do not investigate the explicit context of words and are unable to model diverse components of a sentence. Hence, the full potential of such diverse data has not been explored. In this research, a Context-Sensitive Multi-Tier Deep Learning Framework (CS-MDF) is proposed for sentiment analysis on multimodal data. The CS-MDF uses a three-tier architecture for extracting context-sensitive information. The first tier utilizes Convolutional Neural Network (CNN) for extracting text-based features, 3D-CNN model for extracting visual features and open-Source Media Interpretation by Large feature-space Extraction (openSMILE) tool kit for audio feature extraction.The first tier focuses on extracting the unimodal features from the utterances. This level of extraction ignores context-sensitive data while determining the feature.CNNs are suitable for text data because they are particularly useful for identifying local patterns and dependencies in data.The second tier uses the features extracted from the first tier.The context-sensitive unimodal characteristics are extracted in this tier using the Bi-directional Gated Recurrent Unit (BiGRU), which is used to comprehend inter-utterance links and uncover contextual evidence.The output from tier two is combined and passed to the third tier, which fuses the features from different modalities and trains a single BiGRU model that provides the final classification.This method applies the BiGRU model to sequential data processing, using the advantages of both modalities and capturing their interdependencies.Experimental results obtained on six real-life datasets (Flickr Images dataset, Multi-View Sentiment Analysis dataset, Getty Images dataset, Balanced Twitter for Sentiment Analysis dataset, CMU-MOSI Dataset) show that the proposed CS-MDF model has achieved better performance compared with ten state-of-the-art approaches, which are validated by F1 score, precision, accuracy, and recall metrics.An ablation study is carried out on the proposed framework that demonstrates the viability of the design. The GradCAM visualization technique is applied to visualize the aligned input image-text pairs learned by the proposed CS-MDF model.






























 京公网安备 11010802027423号
京公网安备 11010802027423号