Nature Genetics ( IF 31.7 ) Pub Date : 2023-11-20 , DOI: 10.1038/s41588-023-01559-9
Andrew Dahl 1 , Michael Thompson 2 , Ulzee An 2 , Morten Krebs 3 , Vivek Appadurai 3 , Richard Border 2, 4, 5 , Silviu-Alin Bacanu 6 , Thomas Werge 3, 7, 8 , Jonathan Flint 4 , Andrew J Schork 3, 9, 10 , Sriram Sankararaman 2, 4, 11 , Kenneth S Kendler 6 , Na Cai 12, 13, 14
|
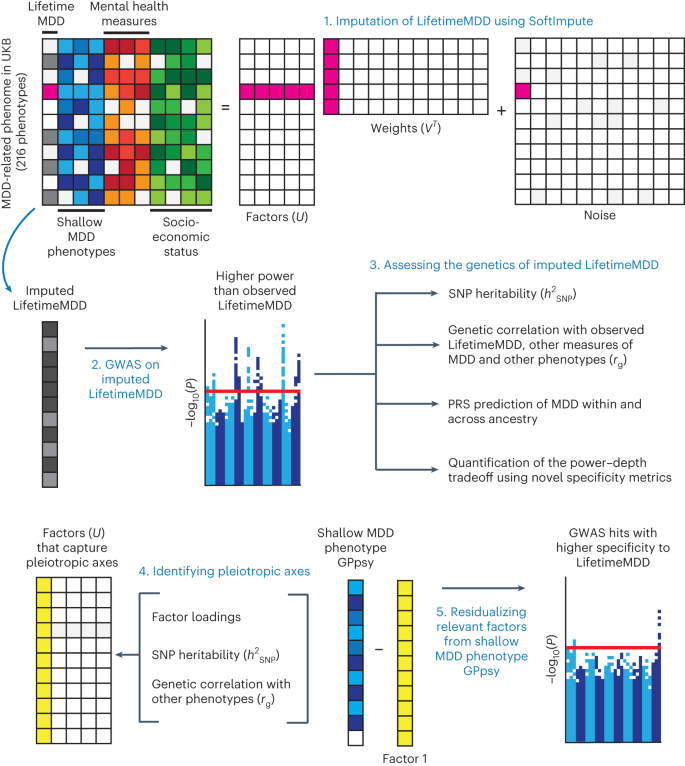
Biobanks often contain several phenotypes relevant to diseases such as major depressive disorder (MDD), with partly distinct genetic architectures. Researchers face complex tradeoffs between shallow (large sample size, low specificity/sensitivity) and deep (small sample size, high specificity/sensitivity) phenotypes, and the optimal choices are often unclear. Here we propose to integrate these phenotypes to combine the benefits of each. We use phenotype imputation to integrate information across hundreds of MDD-relevant phenotypes, which significantly increases genome-wide association study (GWAS) power and polygenic risk score (PRS) prediction accuracy of the deepest available MDD phenotype in UK Biobank, LifetimeMDD. We demonstrate that imputation preserves specificity in its genetic architecture using a novel PRS-based pleiotropy metric. We further find that integration via summary statistics also enhances GWAS power and PRS predictions, but can introduce nonspecific genetic effects depending on input. Our work provides a simple and scalable approach to improve genetic studies in large biobanks by integrating shallow and deep phenotypes.
中文翻译:
表型整合提高了基于生物样本库的重度抑郁症遗传研究的效力并保留了特异性
生物样本库通常包含几种与重度抑郁症 (MDD) 等疾病相关的表型,具有部分不同的遗传结构。研究人员在浅表型 (大样本量、低特异性/敏感性) 和深层 (小样本量、高特异性/敏感性) 表型之间面临复杂的权衡,最佳选择通常不清楚。在这里,我们建议整合这些表型以结合每种表型的优点。我们使用表型插补来整合数百种 MDD 相关表型的信息,这显着提高了英国生物样本库中最深的可用 MDD 表型 LifetimeMDD 的全基因组关联研究 (GWAS) 能力和多基因风险评分 (PRS) 预测准确性。我们使用一种新的基于 PRS 的多效性度量证明,填补保留了其遗传结构的特异性。我们进一步发现,通过汇总统计进行整合也可以增强 GWAS 功效和 PRS 预测,但可以根据输入引入非特异性遗传效应。我们的工作提供了一种简单且可扩展的方法,通过整合浅表型和深表型来改善大型生物库中的遗传研究。


































 京公网安备 11010802027423号
京公网安备 11010802027423号